- Java基礎(chǔ)教程
- Java包(package)
- Eclipse安裝教程
- Java訪問(wèn)權(quán)限
- Java Object類
- Java中final關(guān)鍵字的作用
- Java抽象類
- Java接口
- Java類與類之間的關(guān)系
- Java內(nèi)部類
- Java數(shù)組的定義
- Java訪問(wèn)數(shù)組元素
- Java數(shù)組元素的遍歷
- Java數(shù)組的靜態(tài)初始化
- Java數(shù)組引用數(shù)據(jù)類型
- Java可變長(zhǎng)參數(shù)
- Java數(shù)組擴(kuò)容
- Java數(shù)組的特點(diǎn)
- Java對(duì)象數(shù)組
- Java二維數(shù)組
- Java中arrays工具類
- Java數(shù)組算法
- Java中Collection集合概述
- Java中Collection的基本操作
- Java中List集合
- Java中ArrayList與Vector的區(qū)別
- Java中LinkedList詳解
- Java Set集合與HashSet集合特點(diǎn)
- Java TreeSet集合
- Java Collection集合小結(jié)
- Java中Collections工具類
- Java泛型詳解
- Java中Map集合概述
- Java中Map基本操作
- Java HashMap底層實(shí)現(xiàn)原理
- HashTable和HashMap的區(qū)別
- Java Properties類
- Java TreeMap排序
- Java Map集合小結(jié)
- Java IO流的分類
- Java文件輸入輸出流
- Java緩沖輸入輸出流
- Java數(shù)據(jù)輸入輸出流
- Java打印流與Java裝飾者設(shè)計(jì)模式
- Java對(duì)象輸入輸出流
- Java文件字符輸入輸出流
- Java字符輸入輸出流
- Java緩沖字符輸入輸出流
- Java File類概述
- File類常用操作
- Java線程概述
- Java創(chuàng)建線程的方式
- Java線程基礎(chǔ)操作
- Java線程的生命周期
- Java線程調(diào)度
- Java線程同步
- Java線程安全的類
- Java設(shè)計(jì)模式之生產(chǎn)者消費(fèi)者模式
- Java Timer定時(shí)器
- Java線程死鎖
- Java反射概述
- Java反射類的信息
- Java反射字段信息
- Java反射方法
- Java反射構(gòu)造方法
- Java反射創(chuàng)建實(shí)例
- Java通過(guò)反射訪問(wèn)字段值
- Java通過(guò)反射調(diào)用方法
- Java Properties實(shí)例
- Java內(nèi)存模型的概念
- Java并發(fā)編程
- Java內(nèi)存模型
- Java中Volatile關(guān)鍵字
- Java Volatile關(guān)鍵字使用場(chǎng)景
- JVM內(nèi)存模型
Java內(nèi)存模型的概念
volatile這個(gè)關(guān)鍵字可能很多朋友都聽說(shuō)過(guò),或許也都用過(guò)。在Java 5之前,它是一個(gè)備受爭(zhēng)議的關(guān)鍵字,因?yàn)樵诔绦蛑惺褂盟鶗?huì)導(dǎo)致出人意料的結(jié)果。在Java 5之后,volatile關(guān)鍵字才得以重獲生機(jī)。
volatile關(guān)鍵字雖然從字面上理解起來(lái)比較簡(jiǎn)單,但是要用好不是一件容易的事情。由于volatile關(guān)鍵字是與Java的內(nèi)存模型有關(guān)的,因此在講述volatile關(guān)鍵之前,我們先來(lái)了解一下與內(nèi)存模型相關(guān)的概念和知識(shí),然后分析了volatile關(guān)鍵字的實(shí)現(xiàn)原理,最后給出了幾個(gè)使用volatile關(guān)鍵字的場(chǎng)景。
以下是本文的目錄大綱:
一、Java內(nèi)存模型的概念
二、Java并發(fā)編程中的三個(gè)概念
三、Java內(nèi)存模型
四、深入剖析volatile關(guān)鍵字
五、使用volatile關(guān)鍵字的場(chǎng)景
Java內(nèi)存模型的概念
大家都知道,計(jì)算機(jī)在執(zhí)行程序時(shí),每條指令都是在CPU中執(zhí)行的,而執(zhí)行指令過(guò)程中,勢(shì)必涉及到數(shù)據(jù)的讀取和寫入。由于程序運(yùn)行過(guò)程中的臨時(shí)數(shù)據(jù)是存放在主存(物理內(nèi)存)當(dāng)中的,這時(shí)就存在一個(gè)問(wèn)題,由于CPU執(zhí)行速度很快,而從內(nèi)存讀取數(shù)據(jù)和向內(nèi)存寫入數(shù)據(jù)的過(guò)程跟CPU執(zhí)行指令的速度比起來(lái)要慢的多,因此如果任何時(shí)候?qū)?shù)據(jù)的操作都要通過(guò)和內(nèi)存的交互來(lái)進(jìn)行,會(huì)大大降低指令執(zhí)行的速度。因此在CPU里面就有了高速緩存。
也就是,當(dāng)程序在運(yùn)行過(guò)程中,會(huì)將運(yùn)算需要的數(shù)據(jù)從主存復(fù)制一份到CPU的高速緩存當(dāng)中,那么CPU進(jìn)行計(jì)算時(shí)就可以直接從它的高速緩存讀取數(shù)據(jù)和向其中寫入數(shù)據(jù),當(dāng)運(yùn)算結(jié)束之后,再將高速緩存中的數(shù)據(jù)刷新到主存當(dāng)中。舉個(gè)簡(jiǎn)單的例子,比如下面的這段代碼:
i = i + 1;
當(dāng)線程執(zhí)行這個(gè)語(yǔ)句時(shí),會(huì)先從主存當(dāng)中讀取i的值,然后復(fù)制一份到高速緩存當(dāng)中,然后CPU執(zhí)行指令對(duì)i進(jìn)行加1操作,然后將數(shù)據(jù)寫入高速緩存,最后將高速緩存中i最新的值刷新到主存當(dāng)中。
這個(gè)代碼在單線程中運(yùn)行是沒(méi)有任何問(wèn)題的,但是在多線程中運(yùn)行就會(huì)有問(wèn)題了。在多核CPU中,每條線程可能運(yùn)行于不同的CPU中,因此每個(gè)線程運(yùn)行時(shí)有自己的高速緩存(對(duì)單核CPU來(lái)說(shuō),其實(shí)也會(huì)出現(xiàn)這種問(wèn)題,只不過(guò)是以線程調(diào)度的形式來(lái)分別執(zhí)行的)。本文我們以多核CPU為例。
比如同時(shí)有2個(gè)線程執(zhí)行這段代碼,假如初始時(shí)i的值為0,那么我們希望兩個(gè)線程執(zhí)行完之后i的值變?yōu)?。但是事實(shí)會(huì)是這樣嗎?
可能存在下面一種情況:初始時(shí),兩個(gè)線程分別讀取i的值存入各自所在的CPU的高速緩存當(dāng)中,然后線程1進(jìn)行加1操作,然后把i的最新值1寫入到內(nèi)存。此時(shí)線程2的高速緩存當(dāng)中i的值還是0,進(jìn)行加1操作之后,i的值為1,然后線程2把i的值寫入內(nèi)存。
最終結(jié)果i的值是1,而不是2。這就是著名的緩存一致性問(wèn)題。通常稱這種被多個(gè)線程訪問(wèn)的變量為共享變量。
也就是說(shuō),如果一個(gè)變量在多個(gè)CPU中都存在緩存(一般在多線程編程時(shí)才會(huì)出現(xiàn)),那么就可能存在緩存不一致的問(wèn)題。
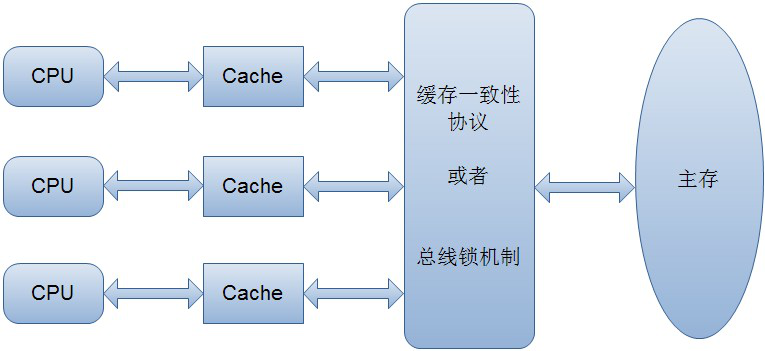
為了解決緩存不一致性問(wèn)題,通常來(lái)說(shuō)有以下2種解決方法:
1、通過(guò)在總線加LOCK#鎖的方式
2、通過(guò)緩存一致性協(xié)議
這2種方式都是硬件層面上提供的方式。
在早期的CPU當(dāng)中,是通過(guò)在總線上加LOCK#鎖的形式來(lái)解決緩存不一致的問(wèn)題。因?yàn)镃PU和其他部件進(jìn)行通信都是通過(guò)總線來(lái)進(jìn)行的,如果對(duì)總線加LOCK#鎖的話,也就是說(shuō)阻塞了其他CPU對(duì)其他部件訪問(wèn)(如內(nèi)存),從而使得只能有一個(gè)CPU能使用這個(gè)變量的內(nèi)存。比如上面例子中 如果一個(gè)線程在執(zhí)行 i = i +1,如果在執(zhí)行這段代碼的過(guò)程中,在總線上發(fā)出了LCOK#鎖的信號(hào),那么只有等待這段代碼完全執(zhí)行完畢之后,其他CPU才能從變量i所在的內(nèi)存讀取變量,然后進(jìn)行相應(yīng)的操作。這樣就解決了緩存不一致的問(wèn)題。
但是上面的方式會(huì)有一個(gè)問(wèn)題,由于在鎖住總線期間,其他CPU無(wú)法訪問(wèn)內(nèi)存,導(dǎo)致效率低下。所以就出現(xiàn)了緩存一致性協(xié)議。最出名的就是Intel 的MESI協(xié)議,MESI協(xié)議保證了每個(gè)緩存中使用的共享變量的副本是一致的。它核心的思想是:當(dāng)CPU寫數(shù)據(jù)時(shí),如果發(fā)現(xiàn)操作的變量是共享變量,即在其他CPU中也存在該變量的副本,會(huì)發(fā)出信號(hào)通知其他CPU將該變量的緩存行置為無(wú)效狀態(tài),因此當(dāng)其他CPU需要讀取這個(gè)變量時(shí),發(fā)現(xiàn)自己緩存中緩存該變量的緩存行是無(wú)效的,那么它就會(huì)從內(nèi)存重新讀取。





關(guān)于我們
- 公司簡(jiǎn)介
- 聯(lián)系方式
教程更新
- tomcat重寫機(jī)制
- Tomcat WebSocket 支持
- 攔截器
- JDBC連接池代碼范例
- JDBC連接池高級(jí)用法
- JDBC連接池的屬性
- JDBC連接池的使用方法
- Tomcat 的 JDBC 連接池
教程更新
- Tomcat Windows 認(rèn)證
- Tomcat Windows 服務(wù)
- server.xml 中的關(guān)鍵配置
- Tomcat安全性注意事項(xiàng)
- Tomcat附加組件
- Tomcat 高級(jí) IO 機(jī)制
- Tomcat虛擬主機(jī)
- Tomcat 基于 APR 的原生庫(kù)
聯(lián)系我們
- 北京校區(qū):北京市通州區(qū)馬駒橋景盛中街17號(hào)順景總部公元B4棟
- 深圳校區(qū):深圳市寶安區(qū)航空路7號(hào)索佳科技園綜合研發(fā)大樓2層
- 上海校區(qū):上海市松江區(qū)歆翱中山科創(chuàng)中心2幢2層
- 廣州校區(qū):廣州市天河區(qū)高科路34號(hào)科誠(chéng)大廈南座5層
- 武漢校區(qū):武漢市東湖高新區(qū)光谷大道108號(hào)久陽(yáng)科技園南樓5層
- 成都校區(qū):成都市武侯區(qū)武興五路智領(lǐng)大廈2單元701
- 西安校區(qū):西安市雁塔區(qū)西安軟件園西區(qū)創(chuàng)新信息大廈A座3層層
- 鄭州校區(qū):鄭州市金水區(qū)燕壽北街86號(hào)怡樂(lè)商務(wù)B座3層
- 南京校區(qū):南京市江寧區(qū)竹山南路555號(hào)有志大廈A2棟302
- 長(zhǎng)沙校區(qū):長(zhǎng)沙市高新區(qū)麓谷企業(yè)廣場(chǎng)F1棟7層
- 免費(fèi)電話:400-8080-105
- 京ICP備09027468號(hào)
-

官方微信
-

官方抖音