很簡單,只需要在主鍵后面添加AUTO_INCREMENT關(guān)鍵字就行了
CREATE TABLE `user`(
?? ?id INT PRIMARY KEY AUTO_INCREMENT,
?? ?username VARCHAR(10),
?? ?`password` VARCHAR(20)
);
剛才,我們在user表中已經(jīng)把主鍵id設(shè)置為自增的了,但是又在表中插入了一條設(shè)置了id值的數(shù)據(jù)
insert into `user` values(1, "張三", "zs666")
那么MySQL會直接忽略掉我們自己設(shè)置的id,繼續(xù)通過自增來設(shè)置插入數(shù)據(jù)的id
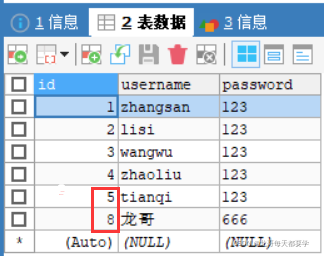
例如id從5直接跳到了8,這是因?yàn)槲覀冎霸趪L試進(jìn)行插入操作時,雖然事務(wù)沒有提交,但是id已經(jīng)自增了
主鍵建議是自增的好。因?yàn)镮nnoDB中的主鍵是聚簇索引,如果主鍵是自增的話,每次插入新的記錄就會順序添加到當(dāng)前索引節(jié)點(diǎn)的后續(xù)位置,當(dāng)一頁寫滿就會自動開辟新的頁。如果不是自增主鍵,可能就會在中間插入,引發(fā)頁的分裂導(dǎo)致產(chǎn)生很多表空間的碎片。可以理解為當(dāng)主鍵是UUID的時候,插入表記錄的時間會更長,占用空間也會更大。
1.任何有業(yè)務(wù)含義的列都有改變的可能性,主鍵一旦帶上了業(yè)務(wù)含義,那么主鍵就有可能發(fā)生變更。而主鍵一旦發(fā)生變更,該記錄數(shù)據(jù)在磁盤上的存儲位置就會發(fā)生改變,甚至有可能會引發(fā)頁分裂導(dǎo)致產(chǎn)生空間碎片。
2.帶有業(yè)務(wù)含義的主鍵就不一定是順序自增的了,這樣就會導(dǎo)致數(shù)據(jù)的插入順序不到有序的,也不能保證后面插入數(shù)據(jù)的主鍵一定比前面的數(shù)據(jù)大。如果出現(xiàn)了后面插入數(shù)據(jù)的主鍵比前面的小的情況,就有可能引發(fā)頁分裂導(dǎo)致產(chǎn)生空間碎片。
表示枚舉的字段一般選用tinyint類型。不選用enum類型主要有兩個原因:
1.enum類型的order by的操作效率低,需要額外的操作。
2.如果枚舉值是數(shù)值類型的,會很容易出現(xiàn)語法陷阱,枚舉的下標(biāo)和數(shù)值很容易會被弄混淆。
如果貨幣單位是分,可以是int類型;如果堅(jiān)持用元,則要用decimal類型。
但是是不能用float和double類型的,因?yàn)檫@兩個類型是以二進(jìn)制存儲的,會有一定的誤差。比如float類型如果你insert一個1234567.23,查詢出來的結(jié)果可能是1234567.25。
時間字段的話需要結(jié)合項(xiàng)目背景,varchar、timestamp、datetime或bigint類型都可以。
1.varchar類型。如果用varchar類型來存時間,優(yōu)點(diǎn)在于顯示直觀,存取都方便。但是缺點(diǎn)也是挺多的,比如插入的數(shù)據(jù)沒有校驗(yàn),某一天你可能會發(fā)現(xiàn)數(shù)據(jù)庫中存了一個2019-06-31的數(shù)據(jù)。其次,做時間比較運(yùn)算時需要用str_to_date()等函數(shù)將其轉(zhuǎn)化為時間類型,除非建立基于函數(shù)的索引,否則這么寫是無法命中索引的,數(shù)據(jù)量一大,查詢效率就會很低。
2.timestamp類型。這個類型是四個字節(jié)的整數(shù),它能表示的時間范圍為1970-01-01 08:00:01到2038-01-19 11:14:07,而2038年以后的時間,是無法用timestamp類型存儲的。但是它有一個優(yōu)勢是它帶有時區(qū)信息的,一旦系統(tǒng)中的時區(qū)發(fā)生改變,項(xiàng)目中的該字段的值也會自己發(fā)生改變。
3.datetime類型。datetime類型的儲存占用8個字節(jié),存儲的時間范圍為1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。顯然,存儲時間范圍更大,但是它存儲的是時間絕對值,不帶有時區(qū)信息。如果改變了數(shù)據(jù)庫的時區(qū),該項(xiàng)的值不會自己發(fā)生變更。
4.bigint類型。這個類型也是8個字節(jié),自己維護(hù)一個時間戳,表示范圍比timestamp類型大多了。缺點(diǎn)就是要自己維護(hù),不大方便。
在實(shí)際應(yīng)用中,一般都是用HDFS來存儲文件的,在MySQL中只會存文件的存放路徑。但是實(shí)際上MySQL是有提供兩個字段類型被涉及用來存放大容量文件的,一個是text類型,一個是blob類型。然而在生產(chǎn)中基本不會使用這兩個類型,主要原因如下:
1.MySQL內(nèi)存臨時表不支持text和blob這樣的大數(shù)據(jù)類型。如果查詢中包含這樣的數(shù)據(jù),那么在排序等操作的時候就不能夠使用內(nèi)存臨時表,只能使用磁盤臨時表,會導(dǎo)致查詢效率低下。
2.這兩種類型會造成binlog的內(nèi)容太多。因?yàn)閿?shù)據(jù)的內(nèi)容比較大,也就會造成binlog的內(nèi)容比較多。我們知道,主從同步是通過binlog來進(jìn)行的,如果binlog過大,就會導(dǎo)致主從同步的效率問題。
1.索引的性能不好。MySQL難以優(yōu)化引用可空列查詢,它會使得索引、索引統(tǒng)計(jì)和值更加復(fù)雜。可空列需要更多的存儲空間,還需要MySQL內(nèi)部進(jìn)行特殊處理。可空列被索引后,每條記錄都需要一個額外的字節(jié)。
2.查詢可能會出現(xiàn)一些不可預(yù)料的結(jié)果。比如說使用count()聚合函數(shù)去統(tǒng)計(jì)一個可為空的字段,那么最后統(tǒng)計(jì)出來的記錄數(shù)可能會和實(shí)際的記錄數(shù)不同。
1)字段最多存放 50 個字符
2)如 varchar(50) 和 varchar(200) 存儲 "jay" 字符串所占空間是一樣的,后者在排序時會消耗更多內(nèi)存

官方微信

官方抖音










 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號