我們現在所使用操作系統都是多任務操作系統(早期使用的DOS操作系統為單任務操作系統),多任務操作指在同一時刻可以同時做多件事(可以同時執行多個程序)。
多進程:每個程序都是一個進程,在操作系統中可以同時執行多個程序,多進程的目的是為了有效的使用CPU資源,每開一個進程系統要為該進程分配相關的系統資源(內存資源);
多線程:線程是進程內部比進程更小的執行單元(執行流|程序片段),每個線程完成一個任務,每個進程內部包含了多個線程每個線程做自己的事情,在進程中的所有線程共享該進程的資源;
主線程:在進程中至少存在一個主線程,其他子線程都由主線程開啟,主線程不一定在其他線程結束后結束,有可能在其他線程結束前結束。Java中的主線程是main線程,是Java的main函數;
當應用場景為計算密集型時:為了將每個cpu充分利用起來,線程數量正常是cpu核數+1,還可以看jdk的使用版本,1.8版本中可以使用cpu核數*2。
當應用場景為io密集型時:做web端開發的時候,涉及到大量的網絡傳輸,不進入持,緩存和與數據庫交互也會存在大量io,當發生io時候,線程就會停止,等待io結束,數據準備好,線程才會繼續執行,所以當io密集時,可以多創建點線程,讓線程等待時候,其他線程執行,更高效的利用cpu效率,他有一個計算公式,套用公式的話,雙核cpu理想的線程數就是20。
采用多線程技術的應用程序可以更好地利用系統資源。主要優勢在于充分利用了CPU的空閑時間片,用盡可能少的時間來對用戶的要求做出響應,使得進程的整體運行效率得到較大提高,同時增強了應用程序的靈活性。由于同一進程的所有線程是共享同一內存,所以不需要特殊的數據傳送機制,不需要建立共享存儲區或共享文件,從而使得不同任務之間的協調操作與運行、數據的交互、資源的分配等問題更加易于解決。
多線程的目的就是為了能提高程序的執行效率提高程序運行速度,但是并發編程并不總是能提高程序運行速度的,而且并發編程可能會遇到很多問題,比如:內存泄漏、死鎖、線程不安全等等。
進程:是正在運行中的程序,是系統進行資源調度和分配的的基本單位。
線程:是進程的子任務,是任務調度和執行的基本單位;
一個程序至少有一個進程,一個進程至少有一個線程,線程依賴于進程而存在;
進程在執行過程中擁有獨立的內存單元,而多個線程共享進程的內存。線程與進程相似,但線程是一個比進程更小的執行單位。
一個進程在其執行的過程中可以產生多個線程。與進程不同的是同類的多個線程共享進程的堆和方法區資源,但每個線程有自己的程序計數器、虛擬機棧和本地方法棧,所以系統在產生一個線程,或是在各個線程之間作切換工作時,負擔要比進程小得多,也正因為如此,線程也被稱為輕量級進程。
a.繼承 Thread 類;b.實現 Runnable 接口;c. 實現Callable接口;d. 使用線程池。
我們可以通過繼承Thread類或者調用Runnable接口來實現線程,因為Java不支持類的多重繼承,但允許你調用多個接口。所以如果你想要繼承其他的類,當然是調用Runnable接口好了。
如果想讓線程池執行任務的話需要實現的Runnable接口或Callable接口。 Runnable接口或Callable接口實現類都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor執行。兩者的區別在于 Runnable 接口不會返回結果但是 Callable 接口可以返回結果。
啟動一個線程需要調用 Thread 對象的 start() 方法;
調用線程的 start() 方法后,線程處于可運行狀態,此時它可以由 JVM 調度并執行,這并不意味著線程就會立即運行;
run() 方法是線程運行時由 JVM 回調的方法,無需手動寫代碼調用;
直接調用線程的 run() 方法,相當于在調用線程里繼續調用了一個普通的方法,并未啟動一個新的線程。
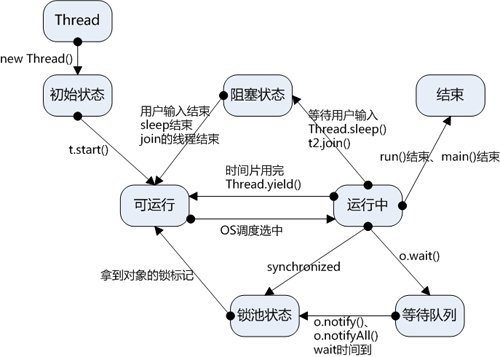
線程通常有五種狀態:創建,就緒,運行,阻塞和死亡狀態
(1)創建狀態(New):新創建了一個線程對象。
(2)就緒狀態(Runnable):線程對象創建后,其他線程調用了該對象的start()方法。該狀態的線程位于可運行線程池中,變得可運行,等待獲取CPU的使用權。
(3)運行狀態(Running):就緒狀態的線程獲取了CPU,執行程序代碼。
(4)阻塞狀態(Blocked):阻塞狀態是線程因為某種原因放棄CPU使用權,暫時停止運行。直到線程進入就緒狀態,才有機會轉到運行狀態。阻塞的情況分三種:
(一)等待阻塞:運行的線程執行wait()方法,JVM會把該線程放入等待池中。(wait會釋放持有的鎖)
(二)同步阻塞:運行的線程在獲取對象的同步鎖時,若該同步鎖被別的線程占用,則JVM會把該線程放入鎖池中。
(三)其他阻塞:運行的線程執行sleep()或join()方法,或者發出了I/O請求時,JVM會把該線程置為阻塞狀態。當sleep()狀態超時、join()等待線程終止或者超時、或者I/O處理完畢時,線程重新轉入就緒狀態。(注意,sleep是不會釋放持有的鎖)
(5)死亡狀態(Dead):線程執行完了或者因異常退出了run()方法,該線程結束生命周期。
多線程編程中一般線程的個數都大于 CPU 核心的個數,而一個 CPU 核心在任意時刻只能被一個線程使用,為了讓這些線程都能得到有效執行,CPU 采取的策略是為每個線程分配時間片并輪轉的形式。當一個線程的時間片用完的時候就會重新處于就緒狀態讓給其他線程使用,這個過程就屬于一次上下文切換。
概括來說就是:當前任務在執行完 CPU 時間片切換到另一個任務之前會先保存自己的狀態,以便下次再切換回這個任務時,可以再加載這個任務的狀態。任務從保存到再加載的過程就是一次上下文切換。
上下文切換通常是計算密集型的。也就是說,它需要相當可觀的處理器時間,在每秒幾十上百次的切換中,每次切換都需要納秒量級的時間。所以,上下文切換對系統來說意味著消耗大量的 CPU 時間,事實上,可能是操作系統中時間消耗最大的操作。
Linux 相比與其他操作系統(包括其他類 Unix 系統)有很多的優點,其中有一項就是,其上下文切換和模式切換的時間消耗非常少。
使用Thread類的setDaemon(true)方法可以將線程設置為守護線程,需要注意的是,需要在調用start()方法前調用這個方法,否則會拋出IllegalThreadStateException異常。
當我們在Java程序中創建一個線程,它就被稱為用戶線程。一個守護線程是在后臺執行并且不會阻止JVM終止的線程。當沒有用戶線程在運行的時候,JVM關閉程序并且退出。一個守護線程創建的子線程依然是守護線程。
Thread類的sleep()和yield()方法將在當前正在執行的線程上運行。所以在其他處于等待狀態的線程上調用這些方法是沒有意義的。這就是為什么這些方法是靜態的。它們可以在當前正在執行的線程中工作,并避免程序員錯誤的認為可以在其他非運行線程調用這些方法。
Windows系統下執行java -jar arthas-boot.jar
Linux系統下解壓arthas,執行ps -ef | grep java找出java進程pid數字
new 一個 Thread,線程進入了新建狀態;調用 start() 方法,會啟動一個線程并使線程進入了就緒狀態,當分配到時間片后就可以開始運行了。 start() 會執行線程的相應準備工作,然后自動執行 run() 方法的內容,這是真正的多線程工作。 而直接執行 run() 方法,會把 run 方法當成一個 main 線程下的普通方法去執行,并不會在某個線程中執行它,所以這并不是多線程工作。
總結: 調用 start 方法方可啟動線程并使線程進入就緒狀態,而 run 方法只是 thread 的一個普通方法調用,還是在主線程里執行.
Callable接口類似于Runnable,從名字就可以看出來,但是Runnable不會返回結果,并且無法拋出返回結果的異常,而Callable功能更強大一些,被線程執行后,可以返回值,這個返回值可以被Future拿到,也就是說,Future可以拿到異步執行任務的返回值。可以認為是帶有返回值的Runnable.Future接口表示異步任務,是還沒有完成的任務給出的未來結果。所以說Callable用于產生結果,Future用于獲取結果。
(1) 搶占式調度策略
Java運行時系統的線程調度算法是搶占式的 (preemptive)。Java運行時系統支持一種簡單的固定優先級的調度算法。如果一個優先級比其他任何處于可運行狀態的線程都高的線程進入就緒狀態,那么運行時系統就會選擇該線程運行。新的優先級較高的線程搶占(preempt)了其他線程。但是Java運行時系統并不搶占同優先級的線程。換句話說,Java運行時系統不是分時的(time-slice)。然而,基于Java Thread類的實現系統可能是支持分時的,因此編寫代碼時不要依賴分時。當系統中的處于就緒狀態的線程都具有相同優先級時,線程調度程序采用一種簡單的、非搶占式的輪轉的調度順序。
(2) 時間片輪轉調度策略
有些系統的線程調度采用時間片輪轉(round-robin)調度策略。這種調度策略是從所有處于就緒狀態的線程中選擇優先級最高的線程分配一定的CPU時間運行。該時間過后再選擇其他線程運行。只有當線程運行結束、放棄(yield)CPU或由于某種原因進入阻塞狀態,低優先級的線程才有機會執行。如果有兩個優先級相同的線程都在等待CPU,則調度程序以輪轉的方式選擇運行的線程。
搶占式。一個線程用完CPU之后,操作系統會根據線程優先級、線程饑餓情況等數據算出一個總的優先級并分配下一個時間片給某個線程執行。
線程調度器是一個操作系統服務,它負責為 Runnable 狀態的線程分配 CPU 時間。一旦我們創建一個線程并啟動它,它的執行便依賴于線程調度器的實現。同上一個問題,線程調度并不受到 Java 虛擬機控制,所以由應用程序來控制它是 更好的選擇(也就是說不要讓你的程序依賴于線程的優先級)。時間分片是指將可用的 CPU 時間分配給可用的 Runnable 線程的過程。分配 CPU 時間可以基于線程優先級或者線程等待的時間。
兩者最主要的區別在于:sleep 方法沒有釋放鎖,而 wait 方法釋放了鎖 。
兩者都可以暫停線程的執行。
wait 通常被用于線程間交互/通信,sleep 通常被用于暫停執行。
wait() 方法被調用后,線程不會自動蘇醒,需要別的線程調用同一個對象上的 notify() 或者 notifyAll() 方法。sleep() 方法執行完成后,線程會自動蘇醒。或者可以使用 wait(long timeout)超時后線程會自動蘇醒。
因為這些方法的調用是依賴鎖對象,而同步代碼塊的鎖對象是任意。鎖而Object代表任意的對象,所以定義在這里面。
使當前線程從執行狀態(運行狀態)變為可執行態(就緒狀態)。當前線程到了就緒狀態,那么接下來具體是哪個個線程會從就緒狀態變成執行狀態就要看系統的分配了。
Thread類的sleep()和yield()方法將在當前正在執行的線程上運行。所以在其他處于等待狀態的線程上調用這些方法是沒有意義的。這就是為什么這些方法是靜態的。它們可以在當前正在執行的線程中工作,并避免程序員錯誤的認為可以在其他非運行線程調用這些方法。
Thread類的sleep()和yield()方法將在當前正在執行的線程上運行。所以在其他處于等待狀態的線程上調用這些方法是沒有意義的。這就是為什么這些方法是靜態的。它們可以在當前正在執行的線程中工作,并避免程序員錯誤的認為可以在其他非運行線程調用這些方法。
線程在運行過程中,有些時候可能需要中斷一些阻塞的線程,類Thread中提供了幾種中斷線程的方法,其中Thread.suspend()和Thread.stop()方法已經過時了,因為這兩個方法是不安全的。Thread.stop(),會直接終止該線程,并且會立即釋放這個線程持有的所有鎖,而這些鎖恰恰是用來維持數據的一致性的,如果此時。寫線程寫入數據時寫到一半,并強行終止,由于此時對象鎖已經被釋放,另一個等待該鎖的讀線程就會讀到這個不一致的對象。Thread.suspend()會導致死鎖,Thread.resume()也不能使用。
Java 提供了很豐富的API 但沒有為停止線程提供 API。JDK 1.0 本來有一些像stop(), suspend() 和 resume()的控制方法但是由于潛在的死鎖威脅因此在后續的JDK 版本中他們被棄用了.之后Java API 的設計者就沒有提供一個兼容且線程安全的方法來停止一個線程。當run() 或者 call() 方法執行完的時候線程會自動結束, 如果要手動結束一個線程.你可以用volatile 布爾變量來退出 run()方法的循環或者是取消任務來中斷線程。
interrupted:查詢當前線程的中斷狀態,并且清除原狀態。如果一個線程被中斷了,第一次調用 interrupted 則返回 true,第二次和后面的就返回 false 了。
isInterrupted僅僅是查詢當前線程的中斷狀態。
1)notify只會隨機選取一個處于等待池中的線程進入鎖池去競爭獲取鎖的機會;
2)notifyAll會讓所有處于等待池的線程全部進入鎖池去競爭獲取鎖的機會;
每一個線程都是有優先級的.一般來說.高優先級的線程在運行時會具有優先權. 但這依賴于線程調度的實現.這個實現是和操作系統相關的(OS dependent)。我們可以定義線程的優先級.但是這并不能保證高優先級的線程會在低優先級的線程前執行。線程優先級是一個int 變量(從 1-10).1 代表最低優先級.10 代表最高優先級。
線程類的構造方法、靜態塊是被new這個線程類所在的線程所調用的,而run方法里面的代碼才是被線程自身所調用的。
舉個例子,假設Thread2中new了Thread1,main函數中new了Thread2,那么:
(1)Thread2的構造方法、靜態塊是main線程調用的,Thread2的run()方法是Thread2自己調用的;
(2)Thread1的構造方法、靜態塊是Thread2調用的,Thread1的run()方法是Thread1自己調用的;
簡單的說,如果異常沒有被捕獲該線程將會停止執行。Thread.UncaughtExceptionHandler 是用于處理未捕獲異常造成線程突然中斷情況的一個內嵌接口。當一個未捕獲異常將造成線程中斷的時候JVM 會使用Thread.getUncaughtExceptionHandler()來查詢線程的UncaughtExceptionHandler 并將線程和異常作為參數傳遞給handler 的uncaughtException()方法進行處理。
(1)線程的生命周期開銷非常高
(2)消耗過多的CPU 資源
如果可運行的線程數量多于可用處理器的數量,那么有線程將會被閑置。大量空閑的線程會占用許多內存,給垃圾回收器帶來壓力,而且大量的線程在競爭CPU 資源時還將產生其他性能的開銷。
(3)降低穩定性
JVM 在可創建線程的數量上存在一個限制,這個限制值將隨著平臺的不同而不同,并且承受著多個因素制約,包括JVM 的啟動參數、Thread 構造函數中請求棧的大小,以及底層操作系統對線程的限制等。如果破壞了這些限制,那么可能拋出OutOfMemoryError 異常。
wait();(強迫一個線程等待)
notify();(通知一個線程繼續執行),
notifyAll()(所有線程繼續執行),
sleep()(強迫一個線程睡眠N毫秒),
join()(等待線程終止)
yield()(線程讓步)等等;
FutureTask 表示一個異步運算的任務。 FutureTask 里面可以傳入一個 Callable 的具體實現類,可以對這
個異步運算的任務的結果進行等待獲取、判斷是否已經完成、取消任務等操作。當然,由于 FutureTask
也是 Runnable 接口的實現類,所以 FutureTask 也可以放入線程池中。
多個線程在正常情況下的運行是互不干擾的,但是CUP對線程的切換是隨機的,這樣線程運行的過程就脫離了我們的控制,如果我們想讓多個線程之間有規律的運行,就需要線程通訊,線程之間通信的可以讓多個線程按照我們預期的運行過程去執行。
1)wait()和notify()
wait(): 當前線程釋放鎖并且進入等待狀態。
notify(): 喚醒當前線程,上面wait() 的時候線程進入了等待狀態,如果我們想讓線程執行需要通過notify()喚醒該線程。
notifyAll(): 喚醒所有進入等待狀態的線程。
2)join()方法
join()方法的作用是使A線程加入B線程中執行,B線程進入阻塞狀態,只有當A線程運行結束后B線程才會繼續執行。
3)volatile關鍵字
volatile 關鍵字是實現線程變量之間真正共享的,就是我們理想中的共享狀態,多個線程同時監控著共享變量,當變量發生變化時其它線程立即改變,具體實現與JMM內存模型有關。
多個線程可以共享進程的堆和方法區資源,既多個線程共享類變量。多個線程共享一個進程的變量時,如果線程對這個變量只有讀操作,沒有更新操作則這個線程沒有線程安全問題。如果線程需要對這個變量進行修改操作,則可能會因為數據更新不及時導致變量信息不準確而引發線程不安全。
當多個線程對同一個資源進行操作的時候就會有線程安全。解決線程安全的核心思想就是加鎖。加鎖有兩種方式:1.JVM提供的鎖,就是synchronized鎖,即同步代碼和同步代碼塊 2.jdk提供的各種鎖,如lock。
在JDK1.1版本中,所有的集合都是線程安全的。但是在1.2及以后的版本中就出現了一些線程不安全的集合,為什么版本升級反而會出現一些線程不安全的集合呢?因為線程不安全的集合普遍比線程安全的集合效率高的多。隨著業務的發展,特別是在WEB應用中,為了提高用戶體驗,減少用戶的等待時間,頁面的響應速度(也就是效率)是優先考慮的。而且對線程不安全的集合加鎖以后也能達到安全的效果(但是效率會低,因為會有鎖的獲取以及等待)。其實在JDK源碼中相同效果的集合線程安全的比線程不安全的就多了一個同步機制,但是效率上卻低了不止一點點,因為效率低,所以已經不太建議使用了。下面列舉一些常用的線程安全的集合。
Vector:就比ArrayList多了個同步化機制。
HashTable:就比HashMap多了個線程安全。
ConcurrentHashMap:是一種高效但是線程安全的集合。
Stack:棧,線程安全,繼承與Vector。
1)修飾實例方法: 作用于當前對象實例加鎖,進入同步代碼前要獲得 當前對象實例的鎖
synchronized void method() {
? //業務代碼
}
2)修飾靜態方法: 也就是給當前類加鎖,會作用于類的所有對象實例 ,進入同步代碼前要獲得 當前 class 的鎖。因為靜態成員不屬于任何一個實例對象,是類成員( static 表明這是該類的一個靜態資源,不管 new 了多少個對象,只有一份)。所以,如果一個線程 A 調用一個實例對象的非靜態 synchronized 方法,而線程 B 需要調用這個實例對象所屬類的靜態 synchronized 方法,是允許的,不會發生互斥現象,因為訪問靜態 synchronized 方法占用的鎖是當前類的鎖,而訪問非靜態 synchronized 方法占用的鎖是當前實例對象鎖。
synchronized void staic method() {
? //業務代碼
}
3)修飾代碼塊 :指定加鎖對象,對給定對象/類加鎖。synchronized(this|object) 表示進入同步代碼庫前要獲得給定對象的鎖。synchronized(類.class) 表示進入同步代碼前要獲得 當前 class 的鎖
synchronized(this) {
? //業務代碼
}
總結:synchronized 關鍵字加到 static 靜態方法和 synchronized(class) 代碼塊上都是是給 Class 類上鎖。
synchronized 關鍵字加到實例方法上是給對象實例上鎖。
盡量不要使用 synchronized(String a) 因為 JVM 中,字符串常量池具有緩存功能!
構造方法不能使用 synchronized 關鍵字修飾。構造方法本身就屬于線程安全的,不存在同步的構造方法一說。
public class Singleton {
private static Singleton uniqueInstance;
// 私有化構造方法
private Singleton() {
}
// 提供getInstance方法
public static Singleton getInstance() {
//先判斷對象是否已經實例過,沒有實例化過才進入加鎖代碼
if (uniqueInstance == null) {
//類對象加鎖
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
同步:功能調用時,在沒有得到結果之前,該調用就不返回或繼續執行后續操作。這時程序是阻塞的,只有接收到返回的值或消息后才往下執行其他的命令。因此,簡單來說,同步就是必須一件一件做事,等前一件事做完了才能做完下一件事。
異步:與同步相對,當一個異步過程調用發出后,調用者在沒有得到結果之前,就可以繼續執行后續操作,當這個調用完成后,一般通過狀態或者回調來通知調用者。
同步塊,這意味著同步塊之外的代碼是異步執行的,這比同步整個方法更提升代 碼的效率。請知道一條原則:同步的范圍越小越好。
當一個線程需要調用對象的wait()方法的時候,這個線程必須擁有該對象的鎖,接著它就會釋放這個對象鎖并進入等待狀態直到其他線程調用這個對象上的notify()方法。同樣的,當一個線程需要調用對象的notify()方法時,它會釋放這個對象的鎖,以便其他在等待的線程就可以得到這個對象鎖。由于所有的這些方法都需要線程持有對象的鎖,這樣就只能通過同步來實現,所以他們只能在同步方法或者同步塊中被調用。
同步就是協同步調,按預定的先后次序進行運行。如:你說完,我再說。這里的同步千萬不要理解成那個同時進行,應是指協同、協助、互相配合。線程同步是指多線程通過特定的設置(如互斥量,事件對象,臨界區)來控制線程之間的執行順序(即所謂的同步)也可以說是在線程之間通過同步建立起執行順序的關系,如果沒有同步,那線程之間是各自運行各自的!
線程互斥是指對于共享的進程系統資源,在各單個線程訪問時的排它性。當有若干個線程都要使用某一共享資源時,任何時刻最多只允許一個線程去使用,其它要使用該資源的線程必須等待,直到占用資源者釋放該資源。線程互斥可以看成是一種特殊的線程同步(下文統稱為同步)。
線程池就是提前創建若干個線程,如果有任務需要處理,線程池里的線程就會處理任務,處理完之后線程并不會被銷毀,而是等待下一個任務。由于創建和銷毀線程都是消耗系統資源的,所以當你想要頻繁的創建和銷毀線程的時候就可以考慮使用線程池來提升系統的性能。
java中經常需要用到多線程來處理一些業務,我們非常不建議單純使用繼承Thread或者實現Runnable接口的方式來創建線程,那樣勢必有創建及銷毀線程耗費資源、線程上下文切換問題。同時創建過多的線程也可能引發資源耗盡的風險,這個時候引入線程池比較合理,方便線程任務的管理。java中涉及到線程池的相關類均在jdk1.5開始的java.util.concurrent包中,涉及到的幾個核心類及接口包括:Executor、Executors、ExecutorService、ThreadPoolExecutor、FutureTask、Callable、Runnable等。
線程池提供了一種限制和管理資源(包括執行一個任務)。 每個線程池還維護一些基本統計信息,例如已完成任務的數量。
線程池的好處如下:
1.降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
2.可有效的控制最大并發線程數,提高系統資源的使用率,同時避免過多資源競爭,避免堵塞。
3.提供定時執行、定期執行、單線程、并發數控制等功能。
1)線程提交到線程池
2)判斷核心線程池是否已經達到設定的數量,如果沒有達到,則直接創建線程執行任務
3)如果達到了,則放在隊列中,等待執行
4)如果隊列已經滿了,則判斷線程的數量是否已經達到設定的最大值,如果達到了,則直接執行拒絕策略
5)如果沒有達到,則創建線程執行任務。
RUNNING :能接受新提交的任務,并且也能處理阻塞隊列中的任務;
SHUTDOWN:關閉狀態,不再接受新提交的任務,但卻可以繼續處理阻塞隊列中已保存的任務。在線程池處于 RUNNING 狀態時,調用 shutdown()方法會使線程池進入到該狀態。(finalize() 方法在執行過程中也會調用shutdown()方法進入該狀態);
STOP:不能接受新任務,也不處理隊列中的任務,會中斷正在處理任務的線程。在線程池處于 RUNNING 或 SHUTDOWN 狀態時,調用 shutdownNow() 方法會使線程池進入到該狀態;
TIDYING:如果所有的任務都已終止了,workerCount (有效線程數) 為0,線程池進入該狀態后會調用 terminated() 方法進入TERMINATED 狀態。
TERMINATED:在terminated() 方法執行完后進入該狀態,默認terminated()方法中什么也沒有做。
Executor就是一個線程池框架,Executor 位于java.util.concurrent.Executors ,提供了用于創建工作線程的線程池的工廠方法。它包含一組用于有效管理工作線程的組件。Executor API 通過 Executors 將任務的執行與要執行的實際任務解耦。
Executor 接口對象能執行我們的線程任務;
Executors 工具類的不同方法按照我們的需求創建了不同的線程池,來滿足業務的需求。
ExecutorService 接口繼承了Executor接口并進行了擴展,提供了更多的方法,我們能夠獲得任務執行的狀態并且可以獲取任務的返回值。
1.newSingleThreadExecutor
創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行。
2.newFixedThreadPoo
創建一個定長線程池,可控制線程最大并發數,超出的線程會在隊列中等待。
3.newCachedThreadPool
創建一個可緩存線程池,如果線程池長度超過處理需要,可靈活回收空閑線程,若無可回收,則新建線程。
4.newScheduledThreadPool
創建一個定長線程池,支持定時及周期性任務執行。
1)newFixedThreadPool和newSingleThreadExecutor: 主要問題是堆積的請求處理隊列可能會耗費非常大的內存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool: 主要問題是線程數最大數是Integer.MAX_VALUE,可能會創建數量非常多的線程,甚至OOM。
3)線程池不允許使用Executors去創建,而是通過ThreadPoolExecutor的方式,這樣的處理方式讓程序員更加明確線程池的運行規則,規避資源耗盡的風險。
ThreadPoolExecutor是線程池的核心實現類,在JDK1.5引入,位于java.util.concurrent包。
通過下面的demo來了解ThreadPoolExecutor創建線程的過程。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 測試ThreadPoolExecutor對線程的執行順序
**/
public class ThreadPoolSerialTest {
public static void main(String[] args) {
//核心線程數
int corePoolSize = 3;
//最大線程數
int maximumPoolSize = 6;
//超過 corePoolSize 線程數量的線程最大空閑時間
long keepAliveTime = 2;
//以秒為時間單位
TimeUnit unit = TimeUnit.SECONDS;
//創建工作隊列,用于存放提交的等待執行任務
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(2);
ThreadPoolExecutor threadPoolExecutor = null;
try {
//創建線程池
threadPoolExecutor = new ThreadPoolExecutor(corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
new ThreadPoolExecutor.AbortPolicy());
//循環提交任務
for (int i = 0; i < 8; i++) {
//提交任務的索引
final int index = (i + 1);
threadPoolExecutor.submit(() -> {
//線程打印輸出
System.out.println("大家好,我是線程:" + index);
try {
//模擬線程執行時間,10s
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//每個任務提交后休眠500ms再提交下一個任務,用于保證提交順序
Thread.sleep(500);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
}
當一個新任務被提交時:
1. 當前活躍線程數<corePoolSize,則創建一個新線程執行新任務;
2. 當前活躍線程數>corePoolSize,且隊列(workQueue)未滿時,則將新任務放入隊列中;
3. 當前活躍線程數>corePoolSize,且隊列(workQueue)已滿,且當前活躍線程數<maximumPoolSize,則繼續創建一個新線程執行新任務;
4. 當前活躍線程數>corePoolSize,且隊列(workQueue)已滿,且當前活躍線程數=maximumPoolSize,則執行拒絕策略(handler);
當任務執行完成后:
1. 超出corePoolSize的空閑線程,在等待新任務時,如果超出了keepAliveTime,則線程會被銷毀;
2. 如果allowCoreThreadTimeOut被設置為true,那么corePoolSize以內的空閑線程,如果超出了keepAliveTime,則同樣會被銷毀。
corePoolSize就是線程池中的核心線程數量,這幾個核心線程在沒有用的時候,也不會被回收
maximumPoolSize就是線程池中可以容納的最大線程的數量
keepAliveTime就是線程池中除了核心線程之外的其他的最長可以保留的時間,因為在線程池中,除了核心線程即使在無任務的情況下也不能被清 除,其余的都是有存活時間的,意思就是非核心線程可以保留的最長的空閑時間
util就是計算這個時間的一個單位。
workQueue就是等待隊列,任務可以儲存在任務隊列中等待被執行,執行的是FIFIO原則(先進先出)。
threadFactory就是創建線程的線程工廠。
handler是一種拒絕策略,我們可以在任務滿了之后,拒絕執行某些任務。
當線程充滿了ThreadPool的有界隊列時,飽和策略開始起作用。飽和策略可以理解為隊列飽和后,處理后續無法入隊的任務的策略。ThreadPoolExecutor可以通過調用setRejectedExecutionHandler來修改飽和策略。
當請求任務不斷的過來,而系統此時又處理不過來的時候,我們需要采取的策略是拒絕服務。RejectedExecutionHandler接口提供了拒絕任務處理的自定義方法的機會。在ThreadPoolExecutor中已經包含四種處理策略。
AbortPolicy策略:該策略會直接拋出異常,阻止系統正常工作。
CallerRunsPolicy 策略:只要線程池未關閉,該策略直接在調用者線程中,運行當前的被丟棄的任務。
DiscardOleddestPolicy策略:該策略將丟棄最老的一個請求,也就是即將被執行的任務,并嘗試再次提交當前任務。
DiscardPolicy策略:該策略默默的丟棄無法處理的任務,不予任何處理。
除了JDK默認提供的四種拒絕策略,我們可以根據自己的業務需求去自定義拒絕策略,自定義的方式很簡單,直接實現RejectedExecutionHandler接口即可。
1.execute()方法用于提交不需要返回值的任務,所以無法判斷任務是否被線程池執行成功與否;
2.submit()方法用于提交需要返回值的任務。線程池會返回一個 Future 類型的對象,通過這個 Future 對象可以判斷任務是否執行成功,并且可以通過 Future 的 get()方法來獲取返回值,get()方法會阻塞當前線程直到任務完成,而使用 get(long timeout,TimeUnit unit)方法則會阻塞當前線程一段時間后立即返回,這時候有可能任務沒有執行完。
線程組ThreadGroup對象中的stop,resume,suspend會導致安全問題,主要是死鎖問題,已經被官方廢棄,多以價值已經大不如以前。
線程組ThreadGroup不是線程安全的,在使用過程中不能及時獲取安全的信息。
shutdownNow():立即關閉線程池(暴力),正在執行中的及隊列中的任務會被中斷,同時該方法會返回被中斷的隊列中的任務列表;
shutdown():平滑關閉線程池,正在執行中的及隊列中的任務能執行完成,后續進來的任務會被執行拒絕策略;
isTerminated():當正在執行的任務及對列中的任務全部都執行(清空)完就會返回true;
線程池將線程和任務進行解耦,線程是線程,任務是任務,擺脫了之前通過 Thread 創建線程時的一個線程必須對應一個任務的限制。在線程池中,同一個線程可以從阻塞隊列中不斷獲取新任務來執行,其核心原理在于線程池對 Thread 進行了封裝,并不是每次執行任務都會調用 Thread.start() 來創建新線程,而是讓每個線程去執行一個“循環任務”,在這個“循環任務”中不停的檢查是否有任務需要被執行,如果有則直接執行,也就是調用任務中的 run 方法,將 run 方法當成一個普通的方法執行,通過這種方式將只使用固定的線程就將所有任務的 run 方法串聯起來。
1.ArrayBlockingQueue是一個基于數組結構的有界阻塞隊列,此隊列按 FIFO(先進先出)原則對元素進行排序。
2.LinkedBlockingQueue一個基于鏈表結構的阻塞隊列,此隊列按FIFO (先進先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。靜態工廠方法Executors.newFixedThreadPool()使用了這個隊列
3.SynchronousQueue 一個不存儲元素的阻塞隊列。每個插入操作必須等到另一個線程調用移除操作,否則插入操作一直處于阻塞狀態,吞吐量通常要高于LinkedBlockingQueue,靜態工廠方法Executors.newCachedThreadPool()使用了這個隊列。
4.PriorityBlockingQueue 一個具有優先級的無限阻塞隊列。
首先是利用好SpringBoot的自動裝配功能,配置好線程池的一些基本參數。
@Configuration
@EnableAsync
public class ThreadPoolTaskConfig {
/*
* 線程池名前綴
*/
private static final String threadNamePrefix = "Api-Async-";
/**
* bean的名稱, 默認為首字母小寫的方法名
* @return
*/
@Bean("taskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
/**
* 默認情況下,在創建了線程池后,線程池中的線程數為0,當有任務來之后,就會創建一個線程去執行任務,
* 當線程池中的線程數目達到corePoolSize后,就會把到達的任務放到緩存隊列當中;
* 當隊列滿了,就繼續創建線程,當線程數量大于等于maxPoolSize后,開始使用拒絕策略拒絕
*/
/*
* 核心線程數(默認線程數)
*/
executor.setCorePoolSize(corePoolSize);
//最大線程數
executor.setMaxPoolSize(maxPoolSize);
//緩沖隊列數
executor.setQueueCapacity(queueCapacity);
//允許線程空閑時間(單位是秒)
executor.setKeepAliveSeconds(keepAliveTime);
executor.setThreadNamePrefix(threadNamePrefix);
//用來設置線程池關閉時候等待所有任務都完成再繼續銷毀其他的Bean
executor.setWaitForTasksToCompleteOnShutdown(true);
//線程池對拒絕任務的處理策略,CallerRunsPolicy:由調用線程(提交任務的線程)處理該任務
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化
executor.initialize();
return executor;
}
}
配置好線程池的基本參數時候,我們就可以使用線程池了, 只要在一個限定域為public的方法頭部加上@Async注解即可。
@Async
public void createOrder() {
System.out.println("執行任務");
}
1)分析任務的特性
任務的性質:CPU 密集型任務、IO 密集型任務和混合型任務。
任務的優先級:高、中、低。
任務的執行時間:長、中、短。
任務的依賴性:是否依賴其他系統資源,如數據庫連接。
2)具體策略
[1]CPU 密集型任務配置盡可能小的線程,如配置N(CPU核心數)+1個線程的線程池。
[2]IO 密集型任務則由于線程并不是一直在執行任務,則配置盡可能多的線程,如2*N(CPU核心數)。
[3]混合型任務如果可以拆分,則將其拆分成一個 CPU 密集型任務和一個 IO 密集型任務。只要這兩個任務執行的時間相差不是太大,那么分解后執行的吞吐率要高于串行執行的吞吐率;如果這兩個任務執行時間相差太大,則沒必要進行分解。
[4]優先級不同的任務可以使用優先級隊列 PriorityBlockingQueue 來處理,它可以讓優先級高的任務先得到執行。但是,如果一直有高優先級的任務加入到阻塞隊列中,那么低優先級的任務可能永遠不能執行。
[5]執行時間不同的任務可以交給不同規模的線程池來處理,或者也可以使用優先級隊列,讓執行時間短的任務先執行。
[6]依賴數據庫連接池的任務,因為線程提交 SQL 后需要等待數據庫返回結果,線程數應該設置得較大,這樣才能更好的利用 CPU。
[7]建議使用有界隊列,有界隊列能增加系統的穩定性和預警能力。可以根據需要設大一點,比如幾千。使用無界隊列,線程池的隊列就會越來越大,有可能會撐滿內存,導致整個系統不可用。
從字面上理解ThreadLocal就是“線程局部變量”的意思。簡單的說就是,一個ThreadLocal在一個線程中是共享的,在不同線程之間又是隔離的(每個線程都只能看到自己線程的值)。
學習一個類之前我們需要了解一個類的API,這也是我們學習類的入口。而ThreadLocal類的API相當簡單。
在這里面比較重要的就是,get、set、remove了,這三個方法是對這個變量進行操作的關鍵。set用于賦值操作,get用于獲取變量中的值,remove就是刪除當前這個變量的值。需要注意的是initialValue方法會在第一次調用時被觸發,用于初始化當前變量值,例如在下列代碼中我們需要創建一個ThreadLocal,用于創建一個與線程綁定的Connection對象:
ThreadLocal connection = new ThreadLocal(){
? ? public Connection initialValue(){
? ? ? ? return DriverManager.getConnection(…);
? ? }
});
為什么我們將ThreadLocal說成變量,我們姑且可以這么理解,每個ThreadLocal實例中都可以保存一個值(基本數據類型值或者引用類型的引用值),而內部保存的值是可以修改的,而這樣的特性與變量的特性及其相似,變量不就是用來保存一個值的嗎?也就是說每一個ThreadLocal實例就類似于一個變量名,不同的ThreadLocal實例就是不同的變量名,它們內部會存有一個值(暫時這么理解)在后面的描述中所說的“ThreadLocal變量或者是線程變量”代表的就是ThreadLocal類的實例。我們通過重寫initialValue方法指定ThreadLocal變量的初始值,默認情況下initialValue返回的是null。
接下來我們就來動手實踐一下,來理解前面沒有理解的那句話:一個ThreadLocal在一個線程中是共享的,在不同線程之間又是隔離的(每個線程都只能看到自己線程的值)
public class ThreadLocalTest {
?? ?private static ThreadLocal<Integer> num = new ThreadLocal<Integer>() {
?? ??? ?// 重寫這個方法,可以修改“線程變量”的初始值,默認是null
?? ??? ?@Override
?? ??? ?protected Integer initialValue() {
?? ??? ??? ?return 0;
?? ??? ?}
?? ?};
?
?? ?public static void main(String[] args) {
?? ??? ?// 創建一號線程
?? ??? ?new Thread(new Runnable() {
?? ??? ??? ?@Override
?? ??? ??? ?public void run() {
?? ??? ??? ??? ?// 在一號線程中將ThreadLocal變量設置為1
?? ??? ??? ??? ?num.set(1);
?? ??? ??? ??? ?System.out.println("一號線程中ThreadLocal變量中保存的值為:" + num.get());
?? ??? ??? ?}
?? ??? ?}).start();
?
?? ??? ?// 創建二號線程
?? ??? ?new Thread(new Runnable() {
?? ??? ??? ?@Override
?? ??? ??? ?public void run() {
?? ??? ??? ??? ?num.set(2);
?? ??? ??? ??? ?System.out.println("二號線程中ThreadLocal變量中保存的值為:" + num.get());
?? ??? ??? ?}
?? ??? ?}).start();
?
?? ??? ?//為了讓一二號線程執行完畢,讓主線程睡500ms
?? ??? ?try {
?? ??? ??? ?Thread.sleep(500);
?? ??? ?} catch (InterruptedException e) {
?? ??? ??? ?// TODO Auto-generated catch block
?? ??? ??? ?e.printStackTrace();
?? ??? ?}
?? ??? ?
?? ??? ?System.out.println("主線程中ThreadLocal變量中保存的值:" + num.get());
?? ?}
}
上面的代碼中在類中創建了一個靜態的“ThreadLocal變量”,在主線程中創建兩個線程,在這兩個線程中分別設置ThreadLocal變量為1和2。然后等待一號和二號線程執行完畢后,在主線程中查看ThreadLocal變量的值。
程序結果及分析:
程序結果重點看的是主線程輸出的是0,如果是一個普通變量,在一號線程和二號線程中將普通變量設置為1和2,那么在一二號線程執行完畢后在打印這個變量,輸出的值肯定是1或者2(到底輸出哪一個由操作系統的線程調度邏輯有關)。但使用ThreadLocal變量通過兩個線程賦值后,在主線程程中輸出的卻是初始值0。在這也就是為什么“一個ThreadLocal在一個線程中是共享的,在不同線程之間又是隔離的”,每個線程都只能看到自己線程的值,這也就是ThreadLocal的核心作用:實現線程范圍的局部變量。
我們還是將最后結論擺在前面,每個Thread對象都有一個ThreadLocalMap,當創建一個ThreadLocal的時候,就會將該ThreadLocal對象添加到該Map中,其中鍵就是ThreadLocal,值可以是任意類型。也就是說,想要存入的ThreadLocal中的數據實際上并沒有存到ThreadLocal對象中去,而是以這個ThreadLocal實例作為key存到了當前線程中的一個Map中去了,獲取ThreadLocal的值時同樣也是這個道理。這也就是為什么ThreadLocal可以實現線程之間隔離的原因了。
總結:
1)ThreadLocal的作用:實現線程范圍內的局部變量,即ThreadLocal在一個線程中是共享的,在不同線程之間是隔離的。
2)ThreadLocal的原理:ThreadLocal存入值時使用當前ThreadLocal實例作為key,存入當前線程對象中的Map中去。最開始在看源碼之前,我以為是以當前線程對象作為key將對象存入到ThreadLocal中的Map中去。
兩者都用于解決多線程并發訪問。但是ThreadLocal與synchronized有本質的區別。Synchronized用于線程間的數據共享,而ThreadLocal則用于線程間的數據隔離。Synchronized是利用鎖的機制,使變量或代碼塊在某一時該只能被一個線程訪問。而ThreadLocal為每一個線程都提供了變量的副本,使得每個線程在某一時間訪問到的并不是同一個對象,這樣就隔離了多個線程對數據的數據共享。而Synchronized卻正好相反,它用于在多個線程間通信時能夠獲得數據共享。
如果ThreadLocal沒有外部強引用,那么在發生垃圾回收的時候,ThreadLocal就必定會被回收,而ThreadLocal又作為Map中的key,ThreadLocal被回收就會導致一個key為null的entry,外部就無法通過key來訪問這個entry,垃圾回收也無法回收,這就造成了內存泄漏
解決方案:每次使用完ThreadLocal都調用它的remove()方法清除數據,或者按照JDK建議將ThreadLocal變量定義成private static,這樣就一直存在ThreadLocal的強引用,也就能保證任何時候都能通過ThreadLocal的弱引用訪問到Entry的value值,進而清除掉。

官方微信

官方抖音










 京公網安備 11030102010736號
京公網安備 11030102010736號