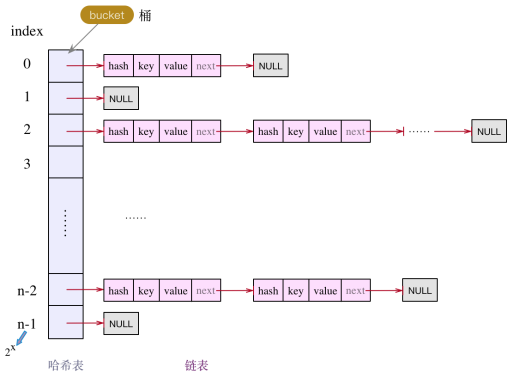
在JDK1.6,JDK1.7中,HashMap采用數(shù)組+鏈表實現(xiàn),而JDK1.8中,HashMap采用數(shù)組+鏈表+紅黑樹實現(xiàn)。以JDK1.7的為例,HashMap里面的每個元素都是通過鍵值對key,value形式存儲的。首先它會通過key來計算對應的哈希值,并把key,value,hash值,下一個元素的地址封裝成一個Entry對象;然后再通過讓哈希值求模的形式來確定Entry對象在數(shù)組中的位置。假設在數(shù)組的下標為2的位置,那么首先會看下標為2的位置上是不是空,如果為空就直接將Entry對象放到2位置;如果下標為2的位置不為空,則會發(fā)生哈希碰撞,這時候需要遍歷該位置元素下的鏈表,看看哈希值和key值是不是都相同,如果相等則覆蓋原來的元素,如果不相等則在頭節(jié)點追加元素形成鏈表形式。
DEFAULT_INITIAL_CAPACITY:默認的初始化容量,1<<4位運算的結果是16,也就是默認的初始化容量為16,容量大小需要是2的整數(shù)倍。
MAXIMUM_CAPACITY:容量的最大值,1 << 30位,2的30次冪。
DEFAULT_LOAD_FACTOR:默認的加載因子。
TREEIFY_THRESHOLD:因為jdk8以后,HashMap底層的存儲結構改為了數(shù)組+鏈表+紅黑樹的存儲結構(之前是數(shù)組+鏈表),剛開始存儲元素產生碰撞時會在碰撞的數(shù)組后面掛上一個鏈表,當鏈表長度大于這個參數(shù)時,鏈表就可能會轉化為紅黑樹(為什么是可能后面還有一個參數(shù),需要他們兩個都滿足的時候才會轉化)。
UNTREEIFY_THRESHOLD:介紹上面的參數(shù)時,我們知道當長度過大時可能會產生從鏈表到紅黑樹的轉化,但是,元素不僅僅只能添加還可以刪除,或者另一種情況,擴容后該數(shù)組槽位置上的元素數(shù)據(jù)不是很多了,還使用紅黑樹的結構就會很浪費,所以這時就可以把紅黑樹結構變回鏈表結構,什么時候變,就是元素數(shù)量等于這個值也就是6的時候變回來(元素數(shù)量指的是一個數(shù)組槽內的數(shù)量,不是HashMap中所有元素的數(shù)量)。
MIN_TREEIFY_CAPACITY:鏈表樹化的一個標準,前面說過當數(shù)組槽內的元素數(shù)量大于8時可能會轉化為紅黑樹,之所以說是可能就是因為這個值,當數(shù)組的長度小于這個值的時候,會先去進行擴容,擴容之后就有很大的可能讓數(shù)組槽內的數(shù)據(jù)可以更分散一些了,也就不用轉化數(shù)組槽后的存儲結構了。當然,長度大于這個值并且槽內數(shù)據(jù)大于8時,那就轉化為紅黑樹吧。
引入紅黑樹是為了避免hash性能急劇下降,引起HashMap的讀寫性能急劇下降的場景,正常情況下,一般是不會用到紅黑樹的,在一些極端場景下,假如客戶端實現(xiàn)了一個性能拙劣的hashCode方法,可以保證HashMap的讀寫復雜度不會低于O(lgN)。
加載因子是用于表示數(shù)組中元素填滿的程度。加載因子默認值是0.75。如果不指明初始大小,數(shù)組默認大小即初始容量為16,加載因子loadFactor=0.75,默認初始容量是16*0.75=12。如果填充比為0.5則空間利用率比較低。如果填充比1,說明利用的空間很多,那么形成沖突的機會就會越大,鏈表也會邊長,這樣查找的成本就變高。
關于這個默認容量的選擇,JDK并沒有給出官方解釋,那么這應該就是個經驗值,既然一定要設置一個默認的2^n 作為初始值,那么就需要在效率和內存使用上做一個權衡。這個值既不能太小,也不能太大。太小了就有可能頻繁發(fā)生擴容,影響效率。太大了又浪費空間,不劃算。所以,16就作為一個經驗值被采用了。
不可以。從key映射到HashMap的數(shù)組的對應位置時,會用到一個hash函數(shù):index = HashCode(Key)&(Length - 1);
如果Length的長度為奇數(shù),假設長度為15, Length-1轉換為二進制后為 1110 ,假設此時的hashCode為 101110001110101110 1011, 做&運算得出的index結果為: 101110001110101110 1010, 如果此時的hashCode為101110001110101110 1010,同樣的做&運算,發(fā)現(xiàn)得出啦相同的index。看似好像沒有很大的問題,因為我們在用hashmap的時候出現(xiàn)哈希值相等的情況還是有的。再看一種情況,如果長度為9,那么Length-1 轉換為二進制的結果為1000, 那么只要hashCode的最后三位不相同,計算出來的結果仍然是一樣的,那么此時的index會更容易出現(xiàn),并且此時的index的最后三位永遠不會出現(xiàn)111的情況,這樣的話,不符合Hash算法的均勻分布原則。
假如長度為16,那么length-1對應的二進制位1111,那么計算哈希code的時不會影響index出現(xiàn)的概率,符合均勻分布的設計原則。 因此HashMap的長度一般為2^n, 默認的長度為16。
如果一直不進行擴容的話,鏈表就會越來越長,這樣查找的效率很低,因為鏈表的長度很大(當然最新版本使用了紅黑樹后會改進很多),擴容之后,將原來鏈表數(shù)組的每一個鏈表分成奇偶兩個子鏈表分別掛在新鏈表數(shù)組的散列位置,這樣就減少了每個鏈表的長度,增加查找效率。
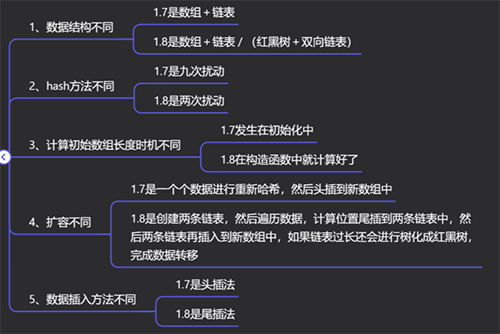
JDK7的HashMap是數(shù)組+鏈表實現(xiàn)的,JDK8的HashMap是數(shù)組+鏈表+紅黑樹實現(xiàn)的;
當某個key-value對需要存儲到數(shù)組中時,需要先生成一個數(shù)組下標index,并且這個index不能越界。在HashMap中,先得到key的hashcode,hashcode是一個數(shù)字,然后通過hashcode & (table.length - 1) 運算得到一個數(shù)組下標index,是通過與運算計算出來一個數(shù)組下標的,而不是通過取余,與運算相比于取余運算速度更快,但是也有一個前提條件,就是數(shù)組的長度得是一個2的冪次方數(shù)。
HashMap在多線程并發(fā)時線程不安全,主要表現(xiàn)在下面兩個方面:
(1) 當向HashMap中put(添加)元素時導致的多線程數(shù)據(jù)不一致
比如有兩個線程 A 和 B ,首先 A 希望插入一個 key-value鍵值對到HashMap 中,它首先計算記錄所要落到的 hash 桶的索引坐標,然后獲取到該桶里面的鏈表頭結點,此時線程 A 的時間片用完了,而此時線程 B 被調度得以執(zhí)行,和線程 A 一樣執(zhí)行,只不過線程 B 成功將記錄插到了桶里面。假設線程 A 插入的記錄計算出來的 hash 桶索引和線程 B 要插入的記錄計算出來的 hash 桶索引是一樣的,那么當線程 B 成功插入之后,線程 A 再次被調度運行時,它依然持有過期的鏈表頭但是它對此一無所知,以至于它認為它應該這樣做,如此一來就覆蓋了線程 B 插入的記錄,這樣線程 B 插入的記錄就憑空消失了,造成了數(shù)據(jù)不一致的行為。
簡單來說就是在多線程環(huán)境下,向HashMap集合中添加元素會存在覆蓋的現(xiàn)象,導致了線程不安全。
(2) 當HashMap進行擴容調用resize()函數(shù)時引起死循環(huán)
HashMap在put的時候,插入的元素超過了容量(由負載因子決定)的范圍就會觸發(fā)擴容操作,就是rehash,這個會重新將原數(shù)組的內容重新hash到新的擴容數(shù)組中,在多線程的環(huán)境下,存在同時其他的元素也在進行put操作,如果hash值相同,可能出現(xiàn)同時在同一數(shù)組下用鏈表表示,造成閉環(huán),導致在get時會出現(xiàn)死循環(huán),所以HashMap是線程不安全的。
HashMap的線程不安全主要體現(xiàn)在下面兩個方面:
1.在JDK1.7中,當并發(fā)執(zhí)行擴容操作時會造成環(huán)形鏈和數(shù)據(jù)丟失的情況。
2.在JDK1.8中,在并發(fā)執(zhí)行put操作時會發(fā)生數(shù)據(jù)覆蓋的情況。
get(key)方法 :
● 首先獲取key的hash值,計算hash&(n-1)得到在數(shù)組中的位置first=tab[hash&(n-1)]
● 先判斷first的key是否與參數(shù)key相等,不等就遍歷后面的鏈表找到相同的key值返回對應的Value值即可
put(key,value)方法:
● 1)判斷鍵值對數(shù)組tab[]是否為空或為null,否則以默認大小resize();
● 2)根據(jù)鍵值key計算hash值,hash值再計算得到插入的數(shù)組索引i,如果tab[i]==null,直接新建節(jié)點添加,否則轉入3
● 3)判斷當前數(shù)組中處理hash沖突的方式為鏈表還是紅黑樹(check第一個節(jié)點類型即可),分別處理。
1. hashMap默認的負載因子是0.75,即如果hashmap中的元素個數(shù)超過了總容量75%,則會觸發(fā)擴容
2. 如果某個桶中的鏈表長度大于等于8了,則會判斷當前的hashmap的容量是否大于64,如果小于64,則會進行擴容;如果大于64,則將鏈表轉為紅黑樹。
1. 擾動函數(shù):促使元素位置分布均勻,減少碰撞幾率
2. 使用final對象,并采用合適的equals()和hashCode()方法
1)ConcurrentHashMap對整個桶數(shù)組進行了分割分段(Segment),然后在每一個分段上都用lock鎖進行保護,相對于HashTable的synchronized鎖的粒度更精細了一些,并發(fā)性能更好,而HashMap沒有鎖機制,不是線程安全的。(JDK1.8之后ConcurrentHashMap啟用了一種全新的方式實現(xiàn),利用CAS算法。)
2)HashMap的鍵值對允許有null,但是ConCurrentHashMap都不允許。
ConcurrentHashMap 結合了 HashMap 和 HashTable 二者的優(yōu)勢。HashMap 沒有考慮同步,HashTable 考慮了同步的問題。但是 HashTable 在每次同步執(zhí)行時都要鎖住整個結構。ConcurrentHashMap 鎖的方式是稍微細粒度的。ConcurrentHashMap 和 Hashtable 的區(qū)別主要體現(xiàn)在實現(xiàn)線程安全的方式上不同。
底層數(shù)據(jù)結構:JDK1.7的 ConcurrentHashMap 底層采用 分段的數(shù)組+鏈表 實現(xiàn),JDK1.8 采用的數(shù)據(jù)結構跟HashMap1.8的結構一樣,數(shù)組+鏈表/紅黑二叉樹。Hashtable 和 JDK1.8 之前的 HashMap 的底層數(shù)據(jù)結構類似都是采用 數(shù)組+鏈表 的形式,數(shù)組是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的;
實現(xiàn)線程安全的方式(重要):① 在JDK1.7的時候,ConcurrentHashMap(分段鎖) 對整個桶數(shù)組進行了分割分段(Segment),每一把鎖只鎖容器其中一部分數(shù)據(jù),多線程訪問容器里不同數(shù)據(jù)段的數(shù)據(jù),就不會存在鎖競爭,提高并發(fā)訪問率。(默認分配16個Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的時候已經摒棄了Segment的概念,而是直接用 Node 數(shù)組+鏈表+紅黑樹的數(shù)據(jù)結構來實現(xiàn),并發(fā)控制使用 synchronized 和 CAS 來操作。(JDK1.6以后 對 synchronized鎖做了很多優(yōu)化) 整個看起來就像是優(yōu)化過且線程安全的 HashMap,雖然在JDK1.8中還能看到 Segment 的數(shù)據(jù)結構,但是已經簡化了屬性,只是為了兼容舊版本;② Hashtable(同一把鎖) :使用 synchronized 來保證線程安全,效率非常低下。當一個線程訪問同步方法時,其他線程也訪問同步方法,可能會進入阻塞或輪詢狀態(tài),如使用 put 添加元素,另一個線程不能使用 put 添加元素,也不能使用 get,競爭會越來越激烈效率越低。
程序運行時能夠同時更新ConccurentHashMap且不產生鎖競爭的最大線程數(shù)。默認為16,且可以在構造函數(shù)中設置。當用戶設置并發(fā)度時,ConcurrentHashMap會使用大于等于該值的最小2冪指數(shù)作為實際并發(fā)度(假如用戶設置并發(fā)度為17,實際并發(fā)度則為32)。
不行,如果key或者value為null會拋出空指針異常。
jdk1.7:Segment+HashEntry來進行實現(xiàn)的;
jdk1.8:放棄了Segment臃腫的設計,采用Node+CAS+Synchronized來保證線程安全;
不需要,get方法采用了unsafe方法,來保證線程安全。
HashTable : 使用了synchronized關鍵字對put等操作進行加鎖;
ConcurrentHashMap JDK1.7: 使用分段鎖機制實現(xiàn);
ConcurrentHashMap JDK1.8: 則使用數(shù)組+鏈表+紅黑樹數(shù)據(jù)結構和CAS原子操作實現(xiàn);

官方微信

官方抖音










 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號