 二叉樹面試題
二叉樹面試題
冒泡排序是在遍歷數組的過程中,每次都要比較連續相鄰的元素,如果某一對相鄰元素是降序(即前面的數大于后面的數),則互換它們的值,否則,保持不變。由于較大的值像“氣泡”一樣逐漸浮出頂部,而較小的值沉向底部,所以叫冒泡排序。
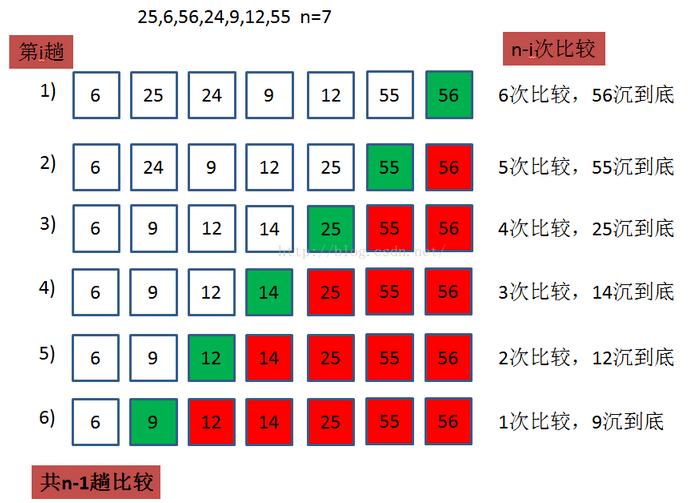
具體實現參考如下源代碼:
//冒泡排序
public static void bubbleSort(int[] list){
int n=list.length;
for(int i=1;i<n;i++){//總共比較n-1趟
for(int j=0;j<n-i;j++){//第i趟比較n-i次
if(list[j]>list[j+1]){
int temp;
temp=list[j];
list[j]=list[j+1];
list[j+1]=temp;
}
}
System.out.print("第"+(i)+"輪排序結果:");
display(list);
}
}
冒泡排序的時間復雜度是O(N2)。 假設被排序的數列中有N個數。遍歷一趟的時間復雜度是O(N),需要遍歷多少次呢? N-1次!因此,冒泡排序的時間復雜度是O(N2)。
冒泡排序是穩定的算法,它滿足穩定算法的定義。所謂算法穩定性指假設在數列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。則這個排序算法是穩定的!
/*
* 冒泡排序(改進版)
*
* 參數說明:
* a -- 待排序的數組
* n -- 數組的長度
*/
public static void bubbleSort2(int[] a, int n) {
int i, j;
int flag; // 標記
for (i = n - 1; i > 0; i--) {
flag = 0; // 初始化標記為0
// 將a[0...i]中最大的數據放在末尾
for (j = 0; j < i; j++) {
if (a[j] > a[j + 1]) {
// 交換a[j]和a[j+1]
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
flag = 1; // 若發生交換,則設標記為1
}
}
if (flag == 0)
break; // 若沒發生交換,則說明數列已有序。
}
}
選擇排序是在遍歷一個待排序的數組過程中,
第一次從 arr[0] 到 arr[n-1] 中選取最小值,與 arr[0] 交換;
第二次從arr[1] 到 arr[n-1]中選取最小值, 與arr[1]交換;
第三次從arr[2] 到 arr[n-1]中選取最小值,與arr[2]交換;
……
第 i 次從 arr[i-1] 到 arr [n-1] 中選取最小值,與arr[i-1]交換;
第n-1次從 arr[n-2] 到 arr [n-1] 中選取最小值,與 arr[n-2] 交換,總共通過n-1次,得到一個按排序碼從小到大排列的有序序列。
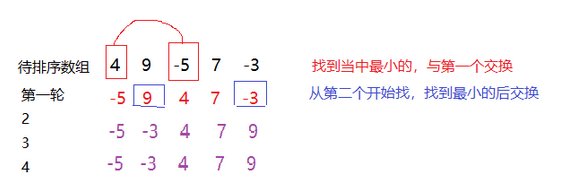
具體實現參考如下源代碼:
public static void choice(int arr[]) {
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
int min = arr[i];
for (int j = i + 1; j < arr.length; j++) {
if (min > arr[j]) {
min = arr[j];
minIndex = j;
}
}
if (minIndex != i) {
arr[minIndex] = arr[i];
arr[i] = min;
}
}
}
A. 11,1,2,12,35,18,30,15
B. 1,2,12,18,15,35,30,11
C. 1,2,11,12,15,18,30,35
D. 1,2,11,12,15,18,35,30
答案:B
解析:第一趟選擇1,將1和12交換位置,序列變為1,15,12,18,2,35,30,11,第二趟選擇2,將2和15交換位置,序列變為1,2,12,18,15,35,30,11;故B正確
A. 數據已按升序排列
B. 數據已按升降序排列
C. 倆者花費時間一樣
答案:C
解析:不管升序還是降序 其比較次數都是整條路徑。
1)插入排序是把n個待排序的元素看成為一個有序表和一個無序表,開始時有序表中只包含一個元素,無序表中包含有n-1個元素,排序過程中每次從無序表中取出第一個元素,將它插入到有序表中的適當位置,使之成為新的有序表,重復n-1次可完成排序過程。
2)具體流程如下:
【1】把數組分成有序a[0]和無序a[1~7]范圍,有序中就一個數肯定是有序的不用管。
【2】把數組分成有序a[0~1]和無序a[2~7]范圍,有序中讓a[1]和a[0]范圍比較,如果a[1]大于a[0],不用交換;如果a[1]小于a[0],交換位置,這樣a[0~1]就是有序的。
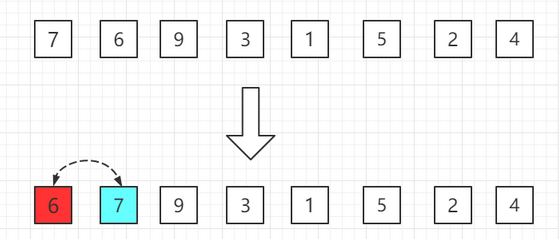
【3】把數組分成有序a[0~2]和無序a[3~7]范圍,有序中讓a[2]和a[0~1]范圍比較。如果a[2]大于a[1],不用交換;如果a[2]小于a[1],交換位置;周而復始再讓a[1]和a[0]比較,這樣a[0~2]就是有序的。

【4】把數組分成有序a[0~3]和無序a[4~7]范圍,有序中讓a[3]和a[0~2]范圍比較。如果a[3]大于a[2],不用交換;如果a[3]小于a[2],交換位置;周而復始再讓a[2]和a[1]比較........這樣a[0~3]就是有序的。
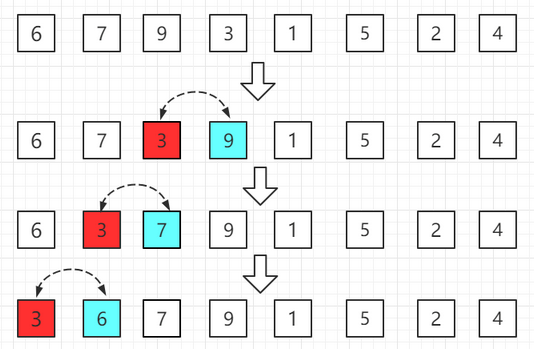
【5】把數組分成有序a[0~4]和無序a[5~7]范圍,有序中讓a[4]和a[0~3]范圍比較。如果a[4]大于a[3],不用交換;如果a[4]小于a[3],交換位置;周而復始再讓a[3]和a[2]比較........這樣a[0~4]就是有序的。
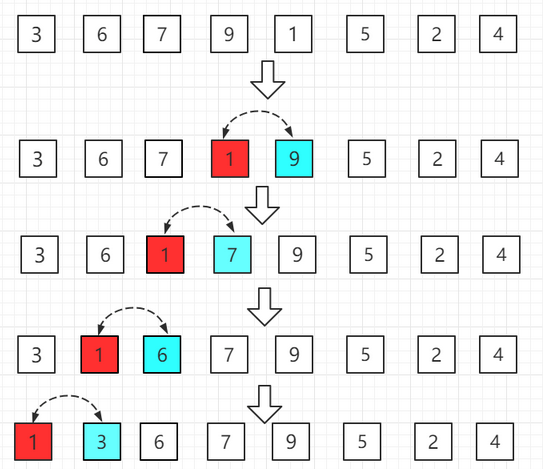
...... 就這樣依次比較到最后一個元素,通俗的說就是一路向左交換。
public static void insertSort(int[ ] arr){
if(arr==null||arr.length<2){
return;
}
//0~0有序的
//0~i有序
for(int i=1;i<arr.length;i++){
for(int j=i-1;j>=0&&arr[j]>arr[j+1];j--){
swap(arr,j,j+1);
}
}
}
A. 6
B. 7
C. 8
D. 9
答案:B
解析:第i趟插入排序可以使前i個元素為n個元素中前i小且有序,執行n-1次后前n-1個元素為n個元素中前n-1小且有序,第n個元素同時也處于正確的位置,故只需n-1趟插入排序。
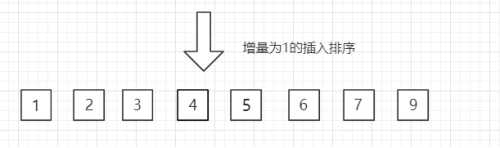
1)希爾排序又稱遞減增量排序算法,是插入排序的改進版。它與插入排序的不同之處在于,它會優先比較距離較遠的元素。希爾排序的基本思想是:先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,待整個序列中的記錄"基本有序"時,再對全體記錄進行依次直接插入排序。希爾排序目的為了加快速度改進了插入排序,交換不相鄰的元素對數組的局部進行排序,并最終用插入排序將局部有序的數組排序。在此我們選擇增量 gap=length/2,縮小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2...1} 來表示。
2) 算法圖解
【1】下面數組的長度length為8,初始增量第一趟 gap = length/2 = 4,即讓第1個數和第5個數比較,第2個數和第6個數進行比較,第3個數和第7個數進行比較,第4個數和第8個數進行比較,最終結果是【1 5 2 3 7 6 9 4】

【2】第二趟,gap=gap/2=2,增量縮小為 2。即讓第1個數、第3個數、第5個數和第7個數進行比較,第2個數、第4個數、第6個數和第8個數進行比較,最終結果是【1 3 2 4 7 5 9 6】

【3】第三趟,gap=gap/2=1,增量縮小為 1。所有的數進行比較得到的結果【1 2 3 4 5 6 7 9】
public static void shellSort(int[] args) {
for (int gap = args.length / 2; gap > 0; gap /= 2) {
// 從第gap個元素,逐個對其所在組進行直接插入排序操作
for (int i = gap; i < args.length; i++) {
int j = i;
int temp = args[j];
if (args[j] < args[j - gap]) {
while (j - gap >= 0 && temp < args[j - gap]) {
// 移動法
args[j] = args[j - gap];
j -= gap;
}
args[j] = temp;
}
}
}
}
A. 直接插入排序
B. 折半插入排序
C. 快速排序
D. 歸并排序
答案: A
解析: 希爾排序的思想是:先將待排元素序列分割成若干個子序列(由相隔某個“增量”的元素組成),分別進行直接插入排序,然后依次縮減增量再進行排序,待整個序列中的元素基本有序(增量足夠小)時,再對全體元素進行一次直接插入排序。
A. 40,50,20,95
B. 15,40,60,20
C. 15,20,40,45
D. 45,40,15,20
答案: B
解析:希爾排序屬于插入類排序,是將整個有序序列分割成若干小的子序列分別進行插入排序。排序過程是先取一個正整數d1<n,把所有序號相隔d1的數組元素放一組,組內進行直接插入排序;然后取d2<d1,重復上述分組和排序操作;直至di = 1,即所有記錄放進一個組中排序為止。
題目中:d = 4,排序之后為:15,40,60,20,50,70,95,45
d = 2,排序之后為:15,20,50,40,60,45,95,70
d = 3,排序之后為:15,20,40,45,50,60,70,95
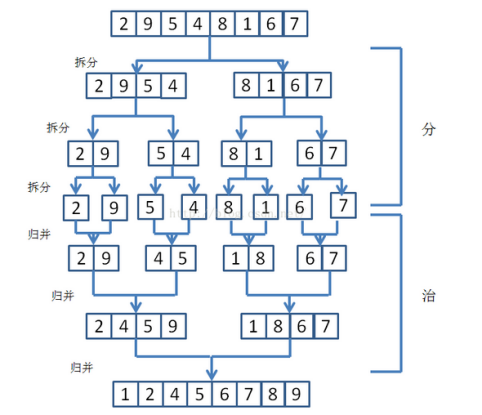
1)歸并排序采用了分治策略(divide-and-conquer),就是將原問題分解為一些規模較小的相似子問題,然后遞歸解決這些子問題,最后合并其結果作為原問題的解。
2)算法圖解
【1】如圖:先將數組分兩半,左邊是【2、9、5、4】,右邊是【8、1、6、7】;
【2】將左邊【2、9、5、4】繼續分兩半,左邊是【2、9】,右邊是【5、4】;
【3】將【2、9】繼續分兩半,左邊是【2】,右邊是【9】;將【5、4】繼續分兩半,左邊是【5】,右邊是【4】;
【5】創建臨時輔助數組,將左邊【2】和右邊【9】通過比較大小進行合并【2、9】;
【6】創建臨時輔助數組,將左邊【5】和右邊【4】通過比較大小進行合并【4、5】;
【7】創建臨時輔助數組,將左邊【2、9】和右邊【4、5】通過比較大小進行合并【2、4、5、9】,同樣的道理得到【1、8、6、7】;
【8】創建臨時輔助數組,將左邊【2、4、5、9】和右邊【1、8、6、7】通過比較大小進行合并【1、2、4、5、6、7、8、9】;
public static void mergeSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
process(arr, 0, arr.length - 1);
}
public static void process(int[] arr, int L, int R) {
if (L == R) {
return;
}
int mid = L + ((R - L) >> 1);
process(arr, L, mid);
process(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int M, int R) {
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= M) {
help[i++] = arr[p1++];
}
while (p2 <= R) {
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {
arr[L + i] = help[i];
}
}
A. 歸并排序使用了分治策略的思想
B. 歸并排序使用了貪心策略的思想
C. 子序列的長度一定相等
D. 歸并排序是穩定的
答案:AD
解析:暫無解析
A. 6
B. 3
C. 5
D. 4
答案:C
解析:每次將工作區裝滿,共計3110400/400=7776個歸并段,對于n路歸并排序,m個歸并段,需要歸并排序的次數為次,代入數據得到答案為5,所以C正確。
1)快排問題和荷蘭國旗問題類似,快速排序采用的思想是分治思想。主要分兩個步驟:
第一步:從要排序的數組中隨便找出一個元素作為基準(pivot),然后對數組進行分區操作,使基準左邊元素的值都不大于基準值,基準右邊的元素值都不小于基準值。
第二步就是對高段位和地段為兩部分進行遞歸排序。
【1】從【5,3,5,6,2,7】數組中,隨機選取一個數(假設這里選的數是5)與最右邊的7進行交換 ,如下圖
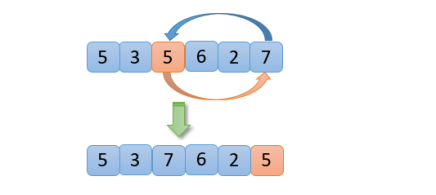
【2】準備好以5為分界點,三個區域分別為小于區、大于區(大于區包含最右側的一個數)和等于區,并準備一個指針,指向最左側的數,如下圖
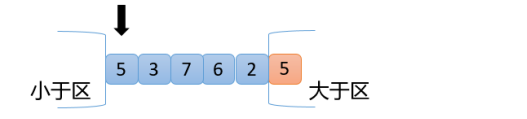
【3】接下來,每次操作都拿指針位置的數與5進行比較,交換原則如下:
-----------------------------------------------------------
原則1:指針位置的數<5
拿指針位置的數與小于區右邊第一個數進行交換
小于區向右擴大一位
指針向右移動一位
原則2:指針位置的數=5
指針向右移動一位
原則3:指針位置的數>5
拿指針位置的數與大于區左邊第一個數進行交換
大于區向左擴大一位
指針位置不動
-------------------------------------------------------
根據圖可以看出指針指向的第一個數是5,5=5,滿足交換原則2,指針向右移動一位,如下圖
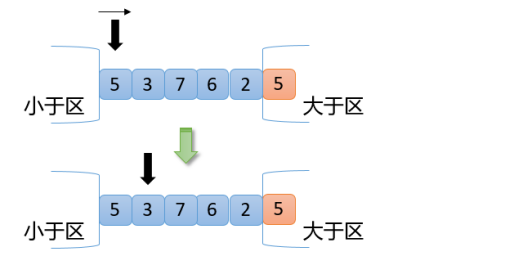
【4】從上圖可知,此時3<5,根據交換原則第1點,拿3和5(小于區右邊第一個數)交換,小于區向右擴大一位,指針向右移動一位,結果如下圖
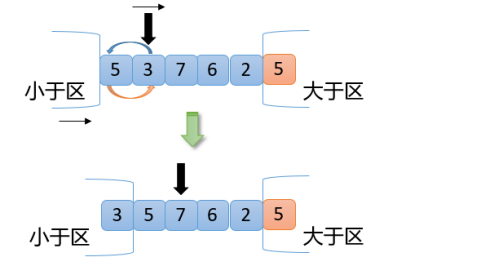
【5】從上圖可以看出,此時7>5,滿足交換原則第3點,7和2(大于區左邊第一個數)交換,大于區向左擴大一位,指針不動,如下圖
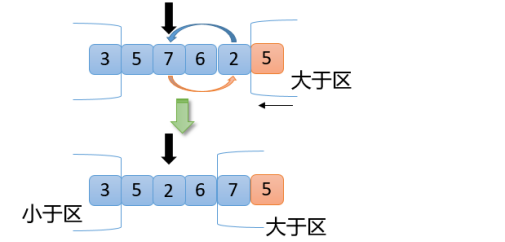
【6】從上圖可以看出,2<5,滿足交換原則第1點,2和5(小于區右邊第一個數)交換,小于區向右擴大一位,指針向右移動一位,得到如下結果
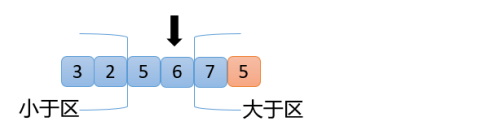
【7】從上圖可以看出,6>5,滿足交換原則第3點,6和6自己換,大于區向左擴大一位,指針位置不動,得到下面結果

【8】此時,指針與大于區相遇,則將指針位置的數6與隨機選出來的5進行交換,就可以得到三個區域:小于區,等于區,大于區,周而復始完成最終的排序
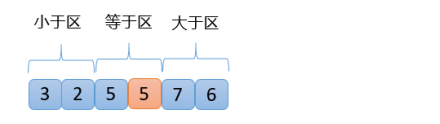
public static void quickSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
quickSort(arr, 0, arr.length - 1);
}
// arr[l..r]排好序
public static void quickSort(int[] arr, int L, int R) {
if (L < R) {
swap(arr, L + (int) (Math.random() * (R - L + 1)), R);
int[] p = partition(arr, L, R);
quickSort(arr, L, p[0] - 1); // < 區
quickSort(arr, p[1] + 1, R); // > 區
}
}
// 這是一個處理arr[l..r]的函數
// 默認以arr[r]做劃分,arr[r] -> p <p ==p >p
// 返回等于區域(左邊界,右邊界), 所以返回一個長度為2的數組res, res[0] res[1]
public static int[] partition(int[] arr, int L, int R) {
int less = L - 1; // <區右邊界
int more = R; // >區左邊界
int index=L;
while (index < more) { // L表示當前數的位置 arr[R] -> 劃分值
if (arr[index] < arr[R]) { // 當前數 < 劃分值
swap(arr, ++less, index++);
} else if (arr[index] > arr[R]) { // 當前數 > 劃分值
swap(arr, --more, index);
} else {
index++;
}
}
swap(arr, more, R);
return new int[] { less + 1, more };
}
快速排序的時間復雜度在最壞情況下是O(N2),平均的時間復雜度是O(N*lgN)。
假設被排序的數列中有N個數。遍歷一次的時間復雜度是O(N),需要遍歷多少次呢? 至少lg(N+1)次,最多N次。 為什么最少是lg(N+1)次? 快速排序是采用的分治法進行遍歷的,我們將它看作一棵二叉樹,它需要遍歷的次數就是二叉樹的深度,而根據完全二叉樹的定義,它的深度至少是lg(N+1)。因此,快速排序的遍歷次數最少是lg(N+1)次。 為什么最多是N次? 這個應該非常簡單,還是將快速排序看作一棵二叉樹,它的深度最大是N。因此,快讀排序的遍歷次數最多是N次。
快速排序是不穩定的算法,它不滿足穩定算法的定義。
堆結構如下圖,堆的實際結構是數組,但是我們在分析它的時候用的是有特殊標準的完全二叉樹來分析。也就是說數組是堆的實際物理結構而完全二叉樹是我們便于分析的邏輯結構。堆有兩種:大根堆和小根堆。每個節點的值都大于其左孩子和右孩子節點的值,稱為大根堆。每個節點的值都小于其左孩子和右孩子節點的值,稱為小根堆。

上面的結構映射成數組就變成了下面這個樣子

1.首先堆的大小是提前知道的,根節點的位置上存儲的數據總是在數組的第一個元素。
2.假設一個非根節點所存儲的數據的索引為i,那么它的父節點存儲的數據所對應的索引就為[(i-1)/2]
3.假設一個節點所存儲的數據的索引為i,那么它的孩子(如果有)所存儲的數據分別所對應的索引為:左孩子是[2*i+1],右孩子是[2*i+2]
第一步,將待排序的數組構造成一個大根堆,假設有下面這個數組:

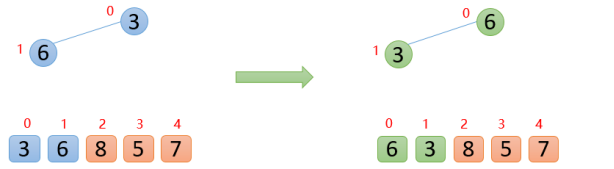
具體思路:第一次保證0~0位置大根堆結構,第二次保證0~1位置大根堆結構,第三次保證0~2位置大根堆結構...直到保證0~n-1位置大根堆結構(每次新插入的數據都與其父節點進行比較,如果插入的數比父節點大,則與父節點交換。周而復始一直向上比較,直到小于等于父節點或者來到了根節點則終止)
【1】插入6的時候,6大于他的父節點3,即arr(1)>arr(0),則交換;此時保證了0~1位置是大根堆結構,如下圖:
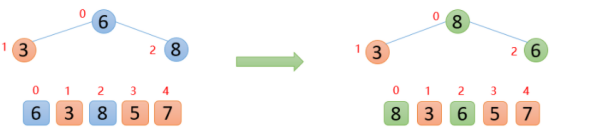
【2】插入8的時候,8大于其父節點6,即arr(2)>arr(0),則交換;此時,保證了0~2位置是大根堆結構,如下圖
【3】插入5的時候,5大于其父節點3,則交換,交換之后,5又發現比8小,所以不交換;此時,保證了0~3位置大根堆結構,如下圖
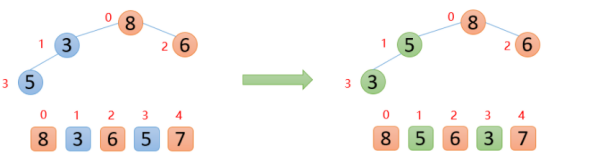
【4】插入7的時候,7大于其父節點5,則交換,交換之后,7又發現比8小,所以不交換;此時整個數組已經是大根堆結構
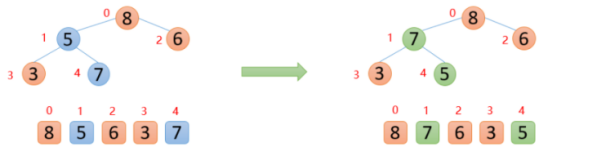
第二步,將根節點的數與末尾的數交換
【1】大根堆中整個數組的最大值就是堆結構的父節點,接下來將根節點的數8與末尾的數5交換

第三步,將剩余的n-1個數再構造成大根堆
如上圖所示,此時最大數8已經來到末尾,讓堆的有效大小減1,后面拿頂端的數與其左右孩子較大的數進行比較,如果頂端的數大于其左右孩子較大的數,則停止,如果頂端的數小于其左右孩子較大的數,則交換;周而復始一直向下比較,直到大于左右孩子較大的數或者沒有孩子節點則終止。
下圖中,5的左右孩子中,左孩子7比右孩子6大,則5與7進行比較,發現5<7,則交換;交換后,發現5已經大于他的左孩子,說明剩余的數已經構成大根堆,

第四步,再將第二步和第三步反復執行,便能得到有序數組
首先遍歷該數組,假設某個數處于index位置,每次都讓index位置和父節點位置的數進行比較,如果大于父節點的值就交換位置,....周而復始,一直到不能往上為止。
for (int i = 0; i < arr.length; i++) { // O(N)
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
先將大根堆的頭節點的數據與堆上的最后一個數交換位置后,把堆有效區的長度減1,再從頭節點開始做向下的比較,每次都和左右孩子中較大值進行比較,如果父節點比最大孩子的值下就交換位置....周而復始,一直到不能往下為止。
// 某個數在index位置,能否往下移動
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下標
while (left < heapSize) { // 下方還有孩子的時候
// 兩個孩子中,誰的值大,把下標給largest
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
// 父和較大的孩子之間,誰的值大,把下標給largest
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
具體實現前面的問題,具體源代碼實現如下:
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//第一步,將待排序的數組構造成一個大根堆
for (int i = 0; i < arr.length; i++) { // O(N)
heapInsert(arr, i); // O(logN)
}
int heapSize = arr.length;
//第二步,將根節點的數與末尾的數交換
swap(arr, 0, --heapSize);
while (heapSize > 0) { // O(N)
//第三步,將剩余的n-1個數再構造成大根堆
heapify(arr, 0, heapSize); // O(logN)
//第二步,將根節點的數與末尾的數交換
swap(arr, 0, --heapSize); // O(1)
}
}
1)桶排序(Bucket sort)或所謂的箱排序,是一個排序算法,工作的原理是將數組分到有限數量的桶里。每個桶再個別排序(有可能再使用別的排序算法或是以遞歸方式繼續使用桶排序進行排序),最后依次把各個桶中的記錄列出來記得到有序序列。桶排序是鴿巢排序的一種歸納結果。當要被排序的數組內的數值是均勻分配的時候,桶排序使用線性時間(Θ(n))。但桶排序并不是比較排序,他不受到O(n log n)下限的影響。
2)算法圖解

A. O(n^2)和O(1)
B. O(nlog(n))和O(1)
C. O(nlog(n))和O(n)
D. O(n^2)和O(n)
答案:B
解析:暫無解析
1)計數排序不是一個基于比較的排序算法。它是用一個數組來統計每種數字出現的次數,然后按照大小順序將其依次放回原數組。但是計數排序有一個很嚴重的問題,就是其只能對整數進行排序,一旦遇到字符串時,就無能為力了。
第一步:找出原始數組【0,2,5,3,7,9,10,3,7,6】中元素值最大的,記為max=10。

第二步:創建一個計數數組count,數組長度是max值加1,其元素默認值都為0。

第三步:遍歷原始數組中的元素,以原始數組中的元素作為計數數組count的索引,以原始數組中的元素出現次數作為計數數組count的元素值。下圖可以得到原始數組【0,2,5,3,7,9,10,3,7,6】中元素0出現1次,元素2出現1次,元素3出現2次,元素5出現1次,元素6出現1次,元素7出現2次,元素9出現1次,元素10出現1次。

第四步:遍歷計數數組count,找出其中元素值大于0的元素,將其對應的索引作為元素值填充到結果數組result中去,每處理一次,計數數組count中的該元素值減1,直到該元素值不大于0,依次處理計數數組count中剩下的元素。
public static void countSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int[] bucket = new int[max + 1];
for (int i = 0; i < arr.length; i++) {
bucket[arr[i]]++;
}
int i = 0;
for (int j = 0; j < bucket.length; j++) {
while (bucket[j]-- > 0) {
arr[i++] = j;
}
}
}
public static void bucketSort(int[] arr){
// 計算最大值與最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
// 計算桶的數量
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 將每個元素放入桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
// 對每個桶進行排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
// 將桶中的元素賦值到原序列
int index = 0;
for(int i = 0; i < bucketArr.size(); i++){
for(int j = 0; j < bucketArr.get(i).size(); j++){
arr[index++] = bucketArr.get(i).get(j);
}
}
}
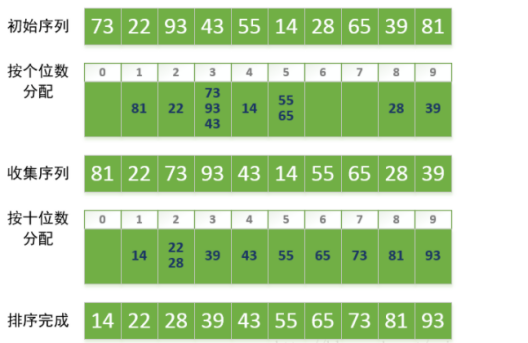
1)基數排序是對桶排序的一種改進,這種改進是讓“桶排序”適合于更大的元素值集合的情況,而不是提高性能。它的基本思想是:將整數按位數切割成不同的數字,然后按每個位數分別比較。
第一步,將所有待比較數值根據個位數的數值分別分配至編號0到9的桶中;
第二步,桶中數據根據先進先出的原則出來,收集完整的序列;
第三步,十位、百位....周而復始
//digit代表最大的數有幾個十進制位
public static void radixSort(int[] arr, int L, int R, int digit) {
//十進制數
final int radix = 10;
int i = 0, j = 0;
// 有多少個數準備多少個輔助空間
int[] bucket = new int[R - L + 1];
for (int d = 1; d <= digit; d++) { // 有多少位就循環幾次
//十進制的數,創建長度為10的數組
int[] count = new int[radix]; // count[0..9]
for (i = L; i <= R; i++) {
j = getDigit(arr[i], d);//獲取該數的個位、十位、百位......上的數
count[j]++;//獲取數組中每個數每位分別是1、2、3....9數分別總共有幾個
}
for (i = 1; i < radix; i++) {
//獲取數組中每個數每位分別是<=1、<=2、<=3....<=9數分別總共有幾個
count[i] = count[i] + count[i - 1];
}
for (i = R; i >= L; i--) {
j = getDigit(arr[i], d);//獲取該數的個位、十位、百位......上的數
bucket[count[j] - 1] = arr[i];//將數放回到輔助空間
count[j]--;
}
for (i = L, j = 0; i <= R; i++, j++) {
arr[i] = bucket[j];
}
}
}
//獲取該數的個位、十位、百位......上的數
public static int getDigit(int x, int d) {
return ((x / ((int) Math.pow(10, d - 1))) % 10);
}
時間復雜度指執行這個算法需要消耗多少時間,也可以認為是對排序數據的總的操作次數。常見的時間復雜度有:常數階O(1),對數階O(log2n),線性階O(n), 線性對數階O(nlog2n),平方階O(n2)。
//時間復雜度O(1)
sum = n*(n+1)/2;
//時間復雜度O(n)
for(int?i = 0; i < n; i++){
System.out.println("%d ",i);
}
//時間復雜度O(n^2)
for(int?i = 0; i < n; i++){
for(int?j = 0; j < n; j++){
System.out.println("%d ",i);
}
}
//運行次數為(1+n)*n/2//時間復雜度O(n^2)
for(int?i = 0; i < n; i++){
for(int?j = i; j < n; j++){
System.out.println("%d ",i);
}
}
//設執行次數為x. 2^x = n 即x = log2n,時間復雜度O(log2n)
int?i = 1, n = 100;
while(i < n){
i = i * 2;
}
O(1)< O(logn)<O(n)<O(nlog2n)<O(n2)<O(n3)<…<O(2n)<O(n!)
空間復雜度是指算法在計算機內執行時所需存儲空間的度量,它也是問題規模n的函數
常見的空間復雜度有:常量空間復雜度O(1)、對數空間復雜度O(log2N)、線性空間復雜度O(n)。
對于一個算法來說,空間復雜度和時間復雜度往往是相互影響的。當追求一個較好的時間復雜度時,可能會使空間復雜度的性能變差,即可能導致占用較多的存儲空間;反之,當追求一個較好的空間復雜度時,可能會使時間復雜度的性能變差,即可能導致占用較長的運行時間。有時我們可以用空間來換取時間以達到目的。
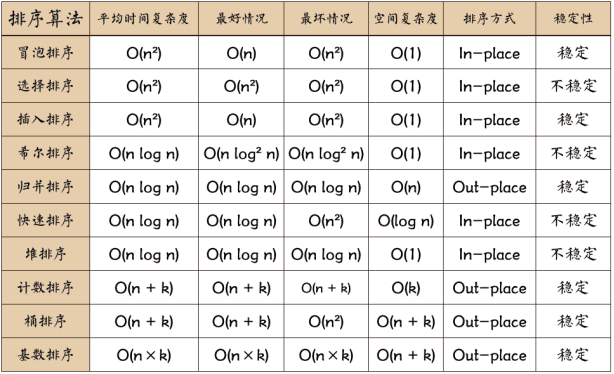
假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序算法是穩定的;否則稱為不穩定的。排序算法是否為穩定的是由算法具體實現決定的。總體上,堆排序、快速排序、希爾排序、直接選擇排序不是穩定的排序算法,而冒泡排序、直接插入排序、歸并排序、基數排序、計數排序、桶排序是穩定的排序算法。
比較類排序:通過比較來決定元素間的相對次序,由于其時間復雜度不能突破O(nlogn),因此也稱為非線性時間比較類排序。如冒泡排序、選擇排序、插入排序、歸并排序、堆排序、快速排序
非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基于比較排序的時間下界,以線性時間運行,因此也稱為線性時間非比較類排序。 如計數排序、基數排序、桶排序
A. 基數排序
B. 冒泡排序
C. 選擇排序
D. 歸并排序
答案:C
解析:選擇排序是不穩定的,如{2*,2,1},第一次遍歷將2*與1互換,結果為{1,2,2*},2與2*位置互換
其余排序均是穩定的
A. 插入排序
B. 快速排序
C. 堆排序
D. 歸并排序
答案:A
解析:插入排序:最佳O(N)
快速排序:最佳O(NlogN)
堆 排序:最佳O(NlogN)
歸并排序:最佳O(NlogN),因此選擇插入排序。

官方微信

官方抖音










 排序面試題
排序面試題 線性表面試題
線性表面試題 圖算法面試題
圖算法面試題 高頻算法面試題
高頻算法面試題 京公網安備 11030102010736號
京公網安備 11030102010736號